-
조회 성능 개선하기 ( ③ DB 최적화, Replication )데이터베이스 2022. 4. 28. 01:08
인덱스 설계에 이어서 이번엔 DB 최적화 부분과 JPA와 함께 MySQL Replicatioin을 구현하는 방법에 대해서 배웠다.
DB 최적화 대상

출처 NEXTSTEP 프로젝트 공방 - Connector (Client)
- MySQL 서버에 접근하기 위해 Application에서 설치하여 사용할 수 있는 모듈들
- 이를 사용하여 MySQL 서버와 통신할 수 있음
- 복수 건의 레코드를 한번의 호출로 집합처리 하거나 두 개 이상의 쿼리를 한 쿼리로 통합 처리 (호출수 줄이기)
- MySQL의 인스턴스 부분
- Client로 부터 들어온 쿼리를 분석하고 최적화하여 실행계획을 만들고 필요한 경우 메모리에 cache
- JDBC Statement : 쿼리 문장을 분석, 컴파일, 실행단계 캐싱
- PreparedStatement : 처음 한번만 세단계를 거친 후 캐시에 담아서 재사용
- DB Connection Pool커넥션을 재사용 하므로서 객체를 생성하는 부분에서 발생하는 대기시간을 줄이고 네트워크 부담을 줄일 수 있음
- 페치사이즈 조정, 페이징 활용(요청사이즈 줄이기)
- Store(Database) Engine
- 데이터를 저장하고 추출
- 파일 시스템에 저장된 데이터가 조회되면 데이터를 메모리에 저장 하여 이후 동일 데이터 조회 시 파일 시스템의 물리적 입출력이 발생하지 않도록
- 서버 파라미터를 튜닝(마지막의 마지막에 적용)
- FileSystem
- SSD 사용
- SQL을 최적화하여 필요이상의 데이터 블록을 읽는 것 방지
SpringDataAccess, MySQL5.7 이상, Public Cloud를 활용하면 상당 부분 최적화 되어있다.
성능 개선 대상 식별하기
## 프로세스 목록 SHOW PROCESSLIST; ## 슬로우 쿼리 확인 SELECT query, exec_count, sys.format_time(avg_latency) AS "avg latency", rows_sent_avg, rows_examined_avg, last_seen FROM sys.x$statement_analysis ORDER BY avg_latency DESC; ## 성능 개선 대상 식별 SELECT DIGEST_TEXT AS query, IF(SUM_NO_GOOD_INDEX_USED > 0 OR SUM_NO_INDEX_USED > 0, '*', '') AS full_scan, COUNT_STAR AS exec_count, SUM_ERRORS AS err_count, SUM_WARNINGS AS warn_count, SEC_TO_TIME(SUM_TIMER_WAIT/1000000000000) AS exec_time_total, SEC_TO_TIME(MAX_TIMER_WAIT/1000000000000) AS exec_time_max, SEC_TO_TIME(AVG_TIMER_WAIT/1000000000000) AS exec_time_avg_ms, SUM_ROWS_SENT AS rows_sent, ROUND(SUM_ROWS_SENT / COUNT_STAR) AS rows_sent_avg, SUM_ROWS_EXAMINED AS rows_scanned, DIGEST AS digest FROM performance_schema.events_statements_summary_by_digest ORDER BY SUM_TIMER_WAIT DESC ## I/O 요청이 많은 테이블 목록 SELECT * FROM sys.io_global_by_file_by_bytes WHERE file LIKE '%ibd'; ## 테이블별 작업량 통계 SELECT table_schema, table_name, rows_fetched, rows_inserted, rows_updated, rows_deleted, io_read, io_write FROM sys.schema_table_statistics WHERE table_schema NOT IN ('mysql', 'performance_schema', 'sys'); ## 총 메모리 사용량 확인 SELECT * FROM sys.memory_global_total; ## 스레드별 메모리 사용량 확인 SELECT thread_id, user, current_allocated FROM sys.memory_by_thread_by_current_bytes LIMIT 10; ## 최근 실행된 쿼리 이력 기능 활성화 UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history' UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history_long' ## 최근 실행된 쿼리 이력 확인 SELECT * FROM performance_schema.events_statements_historyDB 서버 튜닝
메모리 튜닝
#### Thread ## 현재 쓰레드(연결) 개수 확인 mysql> SELECT * FROM performance_schema.threads mysql> SHOW STATUS LIKE '%THREAD%'; #### Caching mysql> SHOW STATUS LIKE '%key%';- Thread
- MySQL은 컨넥션마다 하나의 Thread를 생성하여 요청을 처리
- 이를 조절하여 쓰레드가 생성되고 소멸되면서 겪게 되는 메모리, 각종 자원, 시간 등의 낭비를 줄일 수 있다.
- thread_cache_size는 지나치게 높여둘 필요는 없으며 일반적으로 threads_connected의 피크 치보다 약간 낮은 수치 정도를 설정
- Caching
- Buffer
- Global Buffer : mysqld에서 내부적으로 하나만 확보
- Thread Buffer : Thread(Connection)별로 확보
- Thread Buffer에 많은 메모리를 할당하면 성능이 올라가지만, 설정값 * Connection 수만큼 확보하므로 Connection이 갑자기 늘어나면 메모리가 부족해져 swap이 발생할 수 있음
- Buffer
커넥션 튜닝mysql> SHOW VARIABLES LIKE '%max_connection%'; mysql> SHOW STATUS LIKE '%CONNECT%'; mysql> SHOW STATUS LIKE '%CLIENT%';- connect_timeout
- 클라이언트로부터 접속 요청을 받을 때 몇 초까지 기다릴지를 설정하는 변수
- 기본 값 5초
- Interactive_timeout
- 콘솔이나 터미널 상에서의 클라이언트 접속
- 기본 값으로 8시간
- 1시간 정도로 낮추는 것이 좋다.
- wait_timeout
- 접속한 후 쿼리가 들어올 때까지 기다리는 시간
- 접속이 많은 DBMS에서는 이 값을 낮춰 sleep 상태의 Connection들을 정리하여 전체 성능을 향상
- 값을 너무 낮추게 되면 지나치게 잦은 커넥션이 발생할 수 있으므로, 보통 15~20 사이의 값을 설정
- Aborted client는 2% 아래인 것이 바람직한 상태
- max_connections
- 서버가 허용하는 최대한의 커넥션 수
- 일반적으로 120~250개 정도로 설정
- 접속이 많고 고용량 서버의 경우 높은값 설정도 가능
- 상황에 따라 Too many connection 에러가 발생하지 않도록 적절한 값을 설정
- back_log
- max_connection 설정값 이상의 접속이 발생할 때 얼마만큼의 커넥션을 큐에 보관할지에 대한 설정
- 기본 값은 50
- 접속이 많은 서버의 경우 이 값을 늘린다.
복제 Replication
복제란 복사본을 만드는 것 을 의미하며 DB나 저장소 등에서 자주 사용되는 기술이다. 데이터 손실을 허용하지 않고 장애 시 복구 속도가 빨라야 하는 시스템 혹은 데이터 참조와 갱신 부분이 나뉘어져 있으며 참조가 많은 시스템에서는 적합하지만 데이터 갱신이 많은 시스템에서는 복제 대상 데이터 많아짐에 따라 오버헤드가 높아진다.
Master - Slave Replication
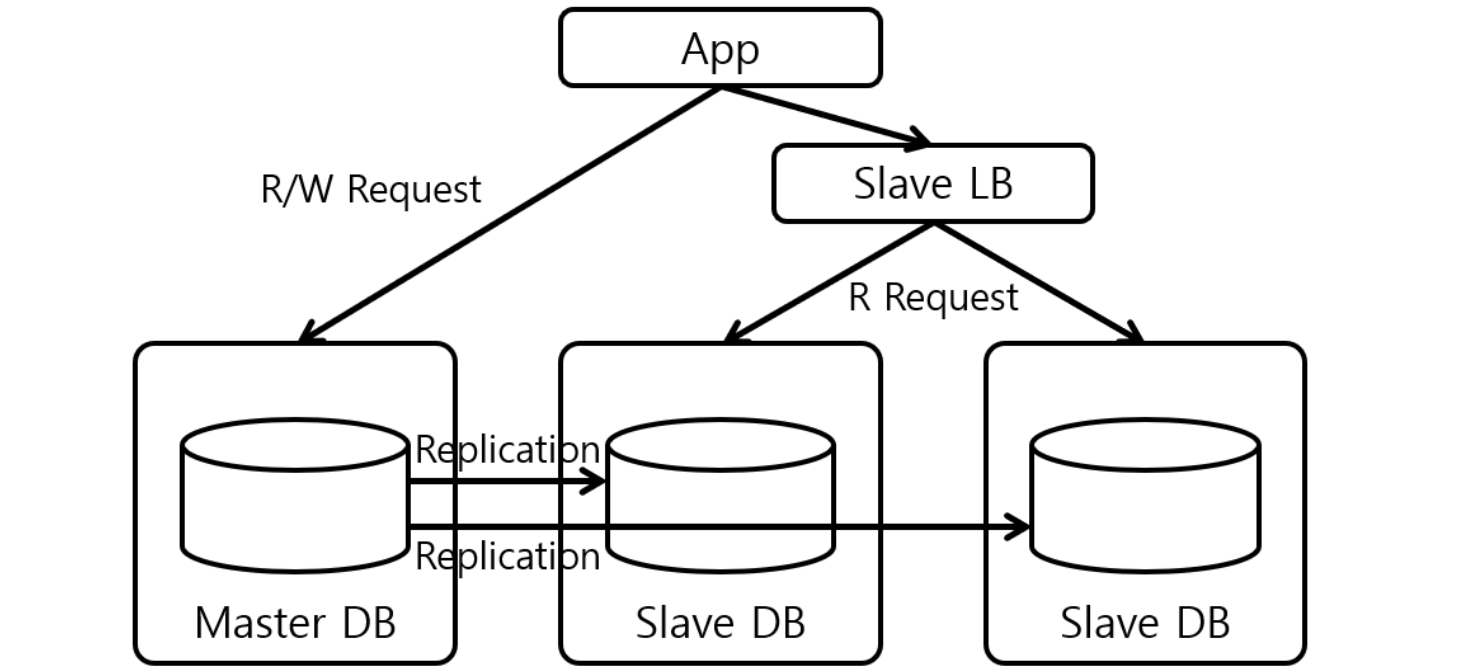
출처 https://ssup2.github.io/theory_analysis/MySQL_Replication/ Master-Slave Replication은 하나의 Master DB와 다수의 Slave DB들을 통해 Replication을 수행하는 방식으로 1:N의 구조를 이룬다. Master DB에 장애가 발생한다면 DB 관리자는 장애가 발생한 Master DB를 다시 기동하여 장애에 대응하거나 Slave DB를 새로운 Master DB로 승격시키는 방법으로 장애에 대응할 수 있으며 2가지 대응 방법 모두 DB 관리자가 개입하여 수동으로 이루어진다.
Master 는 데이터 동시성이 높게 요구되는 트랜잭션을 담당하고 Slave는 데이터 동시성이 꼭 보장될 필요가 없는 경우에 읽기 전용으로 데이터를 가져오는 것을 담당한다.
- Binary Log : DB 변경 내용을 기록하는데 이용하는 Log (MySQL의 Redo 로그와는 별개의 Log)
- Relay Log : Slave DB에 위치하며 Master DB의 Binary Log를 복사해 저장하는데 이용되는 Log
복제방법에는 Async Replication, Semi-Sync Replication 두가지 방법이 존재한다.
① Async Replication

출처 https://ssup2.github.io/theory_analysis/MySQL_Replication/ - Master DB에서의 데이터 변경이 Master DB에 반영
- 변경이력을 Binary Log로 저장
- Slave DB가 복제 위해 Master DB에 Connection
- Master DB는 Dump Thread 하나 생성
- Slave DB는 I/O Thread, SQL Thread 2개의 Thread 생성 (I/O Thread가 Dump Thread와 Connection 맺음)
- Master Dump Thread가 비동기적으로 관련이벤트 Slave DB에게 전달
- Slave IO Thread -> Master Dump Thread -> Binary Log 요청
- 전달받은 Binary Log를 Slave DB 각각의 Relay Log에 복사
- Slave SQL Thread에서 Relay Log를 바탕으로 Slave DB업데이트
- Slave DB 자신의 Binary Log에 기록 (항상 master->slave 방향, 준동시성) ( 읽기 처리를 할 때는 Slave DB를 사용)
② Semi-sync Replication

출처 https://ssup2.github.io/theory_analysis/MySQL_Replication/ Semi-sync Replication은 Master DB가 Slave DB로부터 Relay Log 기록이 완료되었다는 ACK를 받고 Transaction을 진행하는 방식으로 Async Replication 방식에 비해서 좀더 많은 DB 성능저하가 발생하지만, Master-Slave DB 사이의 동기화를 보다 보장할 수 있다. 만약 Master DB가 Slave DB로부터 Relay Log를 받지 못하면 Transaction은 중단되는데 이런 Transcation 중단은 다수의 Slave DB를 두어 최소화 할 수 있다.
- AFTER_COMMIT : Master DB가 업데이트 후에 Slave DB에 변경내용을 보냄
- AFTER_SYNC : Master DB가 Slave DB에 변경내용을 보낸 후에 ACK를 받고나서 업데이트
Replication 구성해보기
① Master DB 구성
#### MySQL 마스터 DB 설정 ## Master DB 생성 $ docker run --name mysql-master -p 13306:3306 -v ~/mysql/master:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=masterpw -d mysql ## Master DB 실행 $ docker exec -it mysql-master /bin/bash $ mysql -u root -p ## Master DB에 복제 유저 생성 mysql> CREATE USER 'replication_user'@'%' IDENTIFIED WITH mysql_native_password by 'replication_pw'; mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%'; mysql> SHOW MASTER STATUS\G *************************** 1. row *************************** File: binlog.000002 Position: 683 //여기서 번호 기억 Binlog_Do_DB: Binlog_Ignore_DB: Executed_Gtid_Set: 1 row in set (0.00 sec) ## root 유저에게 권한 부여(외부 ip(서비스서버와 DB서버가 다른 경우)에서 접근했을 때 데이터 변경 가능하도록) $use mysql; mysql> select user, host from user; +------------------+-----------+ | user | host | +------------------+-----------+ | replication_user | % | | root | % | | mysql.infoschema | localhost | | mysql.session | localhost | | mysql.sys | localhost | | root | localhost | +------------------+-----------+ mysql> create user 'root'@'%' identified by 'masterpw'; ERROR 1396 (HY000): Operation CREATE USER failed for 'root'@'%' mysql> grant all privileges on *.* to 'root'@'%'; Query OK, 0 rows affected (0.00 sec) Mysql >flush privileges; ## 만들고자 하는 데이터 베이스 생성 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ mysql> create database subway; mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | subway | | sys | +--------------------+ mysql> use subway; Database changed ## 데이터 베이스 생성 쿼리 입력 mysql> create table favorite ( -> id bigint auto_increment, -> created_date timestamp, -> modified_date timestamp, -> member_id bigint, -> source_station_id bigint, -> target_station_id bigint, -> primary key (id) -> ); Query OK, 0 rows affected (0.03 sec) mysql> create table line ( -> id bigint auto_increment, -> created_date timestamp, -> modified_date timestamp, -> color varchar(255), -> name varchar(255), -> primary key (id) -> ); Query OK, 0 rows affected (0.02 sec) mysql> create table member ( -> id bigint auto_increment, -> created_date timestamp, -> modified_date timestamp, -> age integer, -> email varchar(255), -> password varchar(255), -> primary key (id) -> ); Query OK, 0 rows affected (0.02 sec) mysql> create table section ( -> id bigint auto_increment, -> distance integer not null, -> down_station_id bigint, -> line_id bigint, -> up_station_id bigint, -> primary key (id) -> ); Query OK, 0 rows affected (0.02 sec) mysql> create table station ( -> id bigint auto_increment, -> created_date timestamp, -> modified_date timestamp, -> name varchar(255), -> primary key (id) -> ); Query OK, 0 rows affected (0.03 sec) mysql> alter table line -> add constraint line_name_unique unique (name); Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table station -> add constraint station_name_unique unique (name); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table section -> add constraint fk_section_down_station_id -> foreign key (down_station_id) -> references station (id); Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table section -> add constraint fk_section_line_id -> foreign key (line_id) -> references line (id); Query OK, 0 rows affected (0.05 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table section -> add constraint fk_section_up_station_id -> foreign key (up_station_id) -> references station (id); Query OK, 0 rows affected (0.09 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> quit Exit② Slave DB 구성
#### MySQL Slave DB 설정 ## Slave DB 생성 $ docker run --name mysql-slave -p 13307:3306 -v ~/mysql/slave:/etc/mysql/conf.d -e MYSQL_ROOT_PASSWORD=slavepw -d mysql ## Slvae DB 실행 $ docker exec -it mysql-slave /bin/bash $ mysql -u root -p ## Slave DB 구성 mysql> SET GLOBAL server_id = 2; ## root 유저에게 권한 부여 mysql> use mysql; mysql> select user, host from user; +------------------+-----------+ | user | host | +------------------+-----------+ | root | % | | mysql.infoschema | localhost | | mysql.session | localhost | | mysql.sys | localhost | | root | localhost | +------------------+-----------+ mysql> grant all privileges on *.* to 'root'@'%'; mysql> flush privileges; ## Master 설정 mysql> CHANGE MASTER TO MASTER_HOST=‘[master ip]’, MASTER_PORT = 13306, MASTER_USER='replication_user', MASTER_PASSWORD='replication_pw', MASTER_LOG_FILE='binlog.000002', MASTER_LOG_POS=[위에서의Positiion]; ## Slave DB 시작 mysql> START SLAVE; mysql> SHOW SLAVE STATUS\G ... Slave_IO_Running: YES Slave_SQL_Running: Yes ## 만약 여기서 Slave_SQL_Running: No의 경우 다음과 같이 error 유발 쿼리를 skip mysql> SLAVE STOP; mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; mysql> SLAVE START; ## 동기화 확인 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | subway | | sys | +--------------------+ mysql> use subway; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +------------------+ | Tables_in_subway | +------------------+ | favorite | | line | | member | | section | | station | +------------------+ mysql> quit Exit③ 서비스 서버의 application.properties에 DB 설정 추가
spring.datasource.hikari.master.username=root spring.datasource.hikari.master.password=masterpw spring.datasource.hikari.master.jdbc-url=jdbc:mysql://[internal-master private ip]:13306/subway?useSSL=false&useUnicode=yes&characterEncoding=UTF-8&serverTimezone=UTC&allowPublicKeyRetrieval=true spring.datasource.hikari.slave.username=root spring.datasource.hikari.slave.password=slavepw spring.datasource.hikari.slave.jdbc-url=jdbc:mysql://[internal-slave private ip]:13307/subway?useSSL=false&useUnicode=yes&characterEncoding=UTF-8&serverTimezone=UTC&allowPublicKeyRetrieval=true나의 EC2 내용을 반영한 application.properties 파일은 다음과 같다. (각기 다른 서버에 Master, Slave DB를 구성한다면 ip를 수정해주면된다.)
spring.profiles.active=local handlebars.suffix=.html handlebars.enabled=true logging.level.org.hibernate.type.descriptor.sql=trace spring.jpa.properties.hibernate.show_sql=true spring.jpa.properties.hibernate.format_sql=true security.jwt.token.secret-key= eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIiLCJuYW1lIjoiSm9obiBEb2UiLCJpYXQiOjE1MTYyMzkwMjJ9.ih1aovtQShabQ7l0cINw4k1fagApg3qLWiB8Kt59Lno security.jwt.token.expire-length= 3600000 spring.datasource.hikari.master.username=root spring.datasource.hikari.master.password=masterpw spring.datasource.hikari.master.jdbc-url=jdbc:mysql://192.168.23.158:13306/subway?serverTimezone=Asia/Seoul&characterEncoding=UTF-8&enabledTLSProtocols=TLSv1.2&useSSL=false&useUnicode=yes&allowPublicKeyRetrieval=true spring.datasource.hikari.slave.username=root spring.datasource.hikari.slave.password=slavepw spring.datasource.hikari.slave.jdbc-url=jdbc:mysql://192.168.23.158:13307/subway?serverTimezone=Asia/Seoul&characterEncoding=UTF-8&enabledTLSProtocols=TLSv1.2&useSSL=false&useUnicode=yes&allowPublicKeyRetrieval=true④ Replication, Data Config 파일 작성
package nextstep.subway.common; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource; import org.springframework.transaction.support.TransactionSynchronizationManager; public class ReplicationRoutingDataSource extends AbstractRoutingDataSource { public static final String DATASOURCE_KEY_MASTER = "master"; public static final String DATASOURCE_KEY_SLAVE = "slave"; @Override protected Object determineCurrentLookupKey() { boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly(); return (isReadOnly) ? DATASOURCE_KEY_SLAVE : DATASOURCE_KEY_MASTER; } }package nextstep.subway.common; import static nextstep.subway.common.ReplicationRoutingDataSource.DATASOURCE_KEY_MASTER; import static nextstep.subway.common.ReplicationRoutingDataSource.DATASOURCE_KEY_SLAVE; import com.zaxxer.hikari.HikariDataSource; import java.util.HashMap; import javax.sql.DataSource; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.boot.autoconfigure.EnableAutoConfiguration; import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.boot.jdbc.DataSourceBuilder; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.context.annotation.Primary; import org.springframework.data.jpa.repository.config.EnableJpaRepositories; import org.springframework.jdbc.datasource.LazyConnectionDataSourceProxy; import org.springframework.transaction.annotation.EnableTransactionManagement; @Configuration @EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class}) @EnableTransactionManagement @EnableJpaRepositories(basePackages = {"nextstep.subway"}) class DataBaseConfig { @Bean @ConfigurationProperties(prefix = "spring.datasource.hikari.master") public DataSource masterDataSource() { return DataSourceBuilder.create().type(HikariDataSource.class).build(); } @Bean @ConfigurationProperties(prefix = "spring.datasource.hikari.slave") public DataSource slaveDataSource() { return DataSourceBuilder.create().type(HikariDataSource.class).build(); } @Bean public DataSource routingDataSource(@Qualifier("masterDataSource") DataSource master, @Qualifier("slaveDataSource") DataSource slave) { ReplicationRoutingDataSource routingDataSource = new ReplicationRoutingDataSource(); HashMap<Object, Object> sources = new HashMap<>(); sources.put(DATASOURCE_KEY_MASTER, master); sources.put(DATASOURCE_KEY_SLAVE, slave); routingDataSource.setTargetDataSources(sources); routingDataSource.setDefaultTargetDataSource(master); return routingDataSource; } @Primary @Bean public DataSource dataSource(@Qualifier("routingDataSource") DataSource routingDataSource) { return new LazyConnectionDataSourceProxy(routingDataSource); } }⑤ 앱 main에 @EnavleJpaRepocitories 삭제 (중복)
여기서 DB 설정에서 @EnableJpaRepositories해주었기 때문에 메인에서는 삭제해준다.
//@EnableJpaRepositories @EnableJpaAuditing @SpringBootApplication public class SubwayApplication { public static void main(String[] args) { SpringApplication.run(SubwayApplication.class, args); } }⑥ @Transactional(readOnly= true)에서는 Slave DB에서 데이터를 받아옴
readOnly = true인 역 조회에서 데이터를 잘 받아오는 것을 확인
추가로 Batch에서 Readonly 설정을 하기 위해서는 별도의 datasource 를 두어야 한다.
@Transactional(readOnly = true) public List<StationResponse> findAllStations(int page) { Pageable pageable = PageRequest.of(0, STATION_SIZE_PER_PAGE, Sort.by("id")); Page<Station> stations = stationRepository.findAllByPage((long) (page * STATION_SIZE_PER_PAGE), pageable); return stations.stream() .map(StationResponse::of) .collect(Collectors.toList()); }
(참고한 사이트)
NextStep 프로젝트 공방
NEXTSTEP
edu.nextstep.camp
https://ssup2.github.io/theory_analysis/MySQL_Replication/
MySQL Replication
MySQL의 HA(High Availabilty)를 위한 Replicaiton 기법들을 분석한다.
ssup2.github.io
https://jojoldu.tistory.com/506
Spring Batch ItemReader에서 Reader DB 사용하기 (feat. AWS Aurora)
일반적으로 서비스가 커지게 되면 DB를 여러대로 늘리게 됩니다. 이때 가장 첫 번째로 고려하는 방법이 Replication 입니다. 즉, 1대의 마스터 DB와 여러대의 Slave DB를 두는 것이죠. 데이터의 변경은
jojoldu.tistory.com
[MySQL] 쿼리 실행 구조 및 쿼리 캐시
쿼리 실행 구조 쿼리 실행구조는 기능별로 다음과 같이 나눠질 수 있습니다. 1) 파서 파서는 사용자 요청으로 들어온 쿼리 문장을 토큰(MySQL이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리
12bme.tistory.com
https://server-talk.tistory.com/240
MySQL Replication(복제) - 단방향 이중화
MySQL Replication을 이용하여 DBMS 단방향 이중화하기 웹서버 부하로 인해 L4를 이용하여 로드밸런싱으로 웹서버의 부하를 해결하였지만, DB 서버의 부하로 인하여 사이트가 느리게 열리는 현상이 발
server-talk.tistory.com
https://jupiny.com/2017/11/07/docker-mysql-replicaiton/
Docker를 이용하여 MySQL Replication 구성해보기
Database Replication? Database Replication은 한 DB 서버의 데이터를 다른 DB 서버들에 복제하는 기술이다. 여기서 복제의 대상이 되는 DB 서버를 보통 master 서버라 하고, 데이터가 복제된 DB 서버를 slave 서버
jupiny.com
https://m.blog.naver.com/dogspecial/221436368729
MySQLSyntaxErrorException: Table doesn't exist
개하!(게스트 하우스 아니고 개특별 하이라는 뜻^^) 오늘은 서비스 테스트를 위해 Mysql 스키마 생성 후 ...
blog.naver.com
https://changun516.tistory.com/55
[Mysql 2059] 로그인 오류 Access denied for user '' @ ''(using password: YES)
오류 해결 Mysql을 Connet하는 경우 아래와 같은 Error 메세지를 만나는 경우가 종종 있습니다. 로그인이 불가하다는건데 문제는 다음과 같습니다. 0. 로그인 정보가 잘못된 경우. 1. 외부 접속을 열어
changun516.tistory.com
https://stackoverflow.com/questions/50177216/how-to-grant-all-privileges-to-root-user-in-mysql-8-0
How to grant all privileges to root user in MySQL 8.0
Tried mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; Getting ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that
stackoverflow.com
Mysql 사용자 조회/추가/생성/삭제
Mysql 사용자 조회 mysql 에 오랜만에 접속해 보면 내가 어떤 사용자를 생성했었는지 간혹 기억이 나지 않을 때가 있다. 아래와 같이 확인하면 된다. mysql> use mysql; Reading table information for completion..
technote.kr
[mysql] 이중화 설정 방법 (replication)
두 개의 리눅스 서버의 sql을 같은 DB처럼 사용하는 것이 이중화입니다. 오늘 설명할 이중화 설정 방법은 mysql에서 사용합니다. Master -> slave (1 -> 2) 단방향으로 동작하는 방식입니다. 1. 설치 된 두
krujy.tistory.com
https://m.blog.naver.com/software705/221337666338
[AWS Mysql] AWS ec2 Mysql 서버구축및 외부접속하기
[ AWS ec2 Mysql 외부접속] ec2 인스턴스에 mysql 서버를 설치하여 외부에서 접속하는 과정에 순서는 ...
blog.naver.com
https://wooiljeong.github.io/server/docker-mysql/
도커(Docker)로 MySQL 서버 구축하기
도커(Docker)로 MySQL 서버 구축하기
wooiljeong.github.io
[linux] MySQL 포트 변경하기
자신의 운영체제에 MySQL을 설치하고 실행하면 기본적으로 3306의 포트번호가 할당된다. 하지만 여러개의 mysql db를 관리해야 하는 시점이 오면 mysql 서버에 여러개의 포트를 할당해야 한다. 예를
zionh.tistory.com
https://jane096.github.io/project/mysql-master-slave-replication/
부하 분산을 위해 MySQL을 Master/Slave로 이중화를 구성해 본 이야기
mysql을 master, slave로 분리하여 읽기와 쓰기의 기능을 분리해 부하를 분산시켜 본 이야기
jane096.github.io
https://teamsmiley.github.io/2018/08/05/docker-mysql-replication/
https://teamsmiley.github.io/2018/08/05/docker-mysql-replication/
docker 로 mysql설치후 리플리케이션 까지. (feat. swarm , docker-machine) 목표 2개의 서버에 도커 스웜을 설치하고 컨테이너를 올린다. docker01 : master db docker02 : slave db를 올린다. 특정 컨테이너는 호스트명
teamsmiley.github.io
http://neomi2428.blogspot.com/2010/08/mysql-slavesqlrunning-no.html
[MySQL] Slave_Sql_Running = No
Master-Slave Replication 환경에서 Master에만 있는 테이블을 변경한다던가, Slave에서 테이블을 DROP하는 작업을 하는 경우 Slave의 Replication이 중단된다. 이 경우 SHOW SLAVE STATUS\...
neomi2428.blogspot.com
'데이터베이스' 카테고리의 다른 글
ELK스택 기본사용법 - ② Kibana (0) 2022.10.31 ELK스택 기본사용법 - ① ElasticSearch (0) 2022.10.26 동시성 제어 (0) 2022.08.18 조회 성능 개선하기 ( ② 인덱스 설계 ) (0) 2022.04.28 조회 성능 개선하기 ( ① 쿼리 최적화 ) (0) 2022.04.28 - Connector (Client)