-
조회 성능 개선하기 ( ② 인덱스 설계 )데이터베이스 2022. 4. 28. 00:11
이번에는 쿼리 최적화에 이어 인덱스 설계를 이용하여 조회성능을 개선하는 방법에 대해서 배웠다.
Table Full Scan vs Index Range Scan
- Table Full Scan
- 시퀀셜 액세스와 Multiblock I/O 방식으로 디스크를 읽어 한 블록에 속한 모든 레코드를 한번에 읽어들임
- 읽을 데이터가 일정량을 넘으면 유리
- 대량데이터 처리
- Index Range Scan
- 랜덤 액세스와 Single Block I/O로 레코드 하나를 읽기 위해 매번 I/O가 발생
- 큰 테이블에서 소량 데이터를 검색할 때 (ex)OLTP)
- 인덱스 갱신 때문에 불필요한 오버헤드 발생 가능
MySQL에서의 Index Range Scan
MySQL InnoDB의 경우 인덱스 스캔 -B트리 인덱스구조가 기본이다.

출처 https://www.getmysql.in/2018/01/mysql-indexes-primary-key-unique-index.html - 수직적 탐색 + 수평적 탐색
- 루트, 브랜치(인덱스키와 자식 노드 정보로 구성된 페이지 단위), 리프 블록으로 이루어짐
- 찾고자 하는 값보다 크거나 같은 값을 만나면 바로 직선 레코드가 가리키는 하위 노드로 이동
- Inno DB의 경우 Secondary Index를 통해 알아낸 Primary Key로 한번 더 수직적 탐색
- 데이터블럭 + 로우번호 ROWID (블럭내 순번)
- Inno DB의 경우 Primary Key가 ROWID 역할(Clustered Index(순차)로 Data Record의 물리적 위치를 알 수 있음)
- 인덱스 튜닝
- 인덱스 스캔 효율화
- 랜덤 액세스 최소화 (인덱스 스캔 후 테이블 레코드 액세스 시 랜덤 I/O 횟수 줄이기)
- 인덱스의 손익분기점 : 10~100만건 이내의 경우 조회 건수가 5~20% 가량
인덱스
① 실행계획 확인하기
EXPLAIN SELECT [필요한 데이터] FROM [조회 대상] WHERE [조건]
- id : SQL문이 수행되는 순서 (드라이빙테이블, 드리븐 테이블 나타냄)
- select_type : SELECT 문의 타입
- SIMPLE : 단순한 SELECT 문 (Union 이나 Sub Query 가 없는 SELECT 문)
- PRIMARY : 서브쿼리를 감싸는 외부 쿼리, UNION이 포함될 경우 첫번째 SELECT 문
- SUBQUERY : 독립적으로 수행되는 서브쿼리 (SELECT, WHERE절에 추가된 서브쿼리)
- DERIVED : FROM 절에 작성된 서브쿼리 또는 Inline View
- UNION : UNION, UNION ALL로 합쳐진 SELECT (UNION 쿼리에서 Primary를 제외한 나머지 SELECT)
- DEPENDENT SUBQUERY : 서브쿼리가 바깥쪽 SELECT쿼리에 정의된 칼럼을 사용 (외곽쿼리에 의존적)
- DEPENDENT UNION : 외부에 정의된 컬럼을 UNION으로 결합된 쿼리에서 사용하는 경우 (외부쿼리에 의존적)
- MATERIALIZED : IN 절 구문의 서브쿼리를 임시 테이블로 생성한 뒤 조인을 수행
- UNCACHEABLE SUBQUERY : RAND(), UUID() 등 조회마다 결과가 달라지는 경우
- type : 조인 혹은 조회 타입
- system : 테이블에 데이터가 없거나 한 개만 있는 경우
- const : 조회되는 데이터가 단 1건일 때
- eq_ref : 조인이 수행될 때 드리븐 테이블의 데이터에 PK 혹은 고유 인덱스로 단 1건의 데이터를 조회할 때
- ref : eq_ref와 같으나 데이터가 2건 이상일 경우
- index : 인덱스 풀 스캔
- range : 인덱스 레인지 스캔
- all : 테이블 풀 스캔
- key : 옵티마이저가 실제로 선택한 인덱스
- rows : SQL문을 수행하기 위해 접근하는 데이터의 모든 행 수
- extra : 추가 정보
- Distinct : 중복 제거시
- Using where : WHERE 절로 필터시
- Using temporary : 데이터의 중간결과를 저장하고자 임시 테이블을 생성, 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우 임시 테이블을 생성
- Using index : 물리적인 데이터 파일을 읽지 않고 인덱스만 읽어서 처리. 커버링 인덱스
- Using filesort : 정렬시
② 인덱스 생성
CREATE INDEX `idx_hobby` ON `subway`.`programmer` (hobby);③ 인덱스 삭제
DROP INDEX `idx_hobby` ON `subway`.`programmer`;- 인덱스 Range Scan을 하기 위해선 인덱스 선두칼럼이 조건절에 존재해야 한다.
- 일정범위를 벗어난 데이터 조회시 Full Scan이 이루어지는데 인덱스 대상이 Primary Key 로 지정되면 Clustered Index(연속적(Sequential) 저장)이 이루어지면서 Range 탐색이 이루어진다.
- 리프 블록 전체를 스캔해야하면 Index Full Scan 한다.
- 인덱스 탐색 대상이 Unique 설정이 되어있으면 등호(=)검색시 하나만 찾으면 더이상 탐색하지 않는 Index Unique Scan(Single Row(constant))
- 인덱스 탐색 대상이 Unique 설정이 되어있더라도 범위 검색시에는 Index Range Scan 처리
- 테이블 액세스를 최소화 하기 위해서는 인덱스에 칼럼을 추가하여 조건절에 해당하는 Primary Key 범위를 줄여 랜덤 액세스 횟수를 줄이도록 한다.
- 새로운 조건문이 추가되어 새로운 인덱스를 생성하면 한 테이블에 여러개의 인덱스가 존재하여 관리하기 어렵고, 데이터 조작 SQL이 사용될 때 트랜잭션 성능을 저하 시킬 수 도 있으므로 기존 인덱스에 인덱스 칼럼을 추가하는 튜닝 기법을 사용하면 테이블의 랜덤 액세스 횟수를 줄일 수 있음
드라이빙 테이블과 드리븐 테이블
SELECT * FROM programmer JOIN covid ON covid.programmer_id = programmer.id- 드라이빙 테이블 : 먼저 접근하는 테이블
- 드리븐 테이블 : 검색 결과를 통해서 그 다음 데이터를 검색하는 테이블
적은 결과가 반환 될 것으로 예상되는 테이블을 드라이빙 테이블로 선정하여 드리븐 테이블의 액세스 반복 횟수를 줄인다.
드라이빙 테이블(조인 연결시 첫번째로 액세스 되는 테이블)과 드리븐 테이블의 순서는 인덱스(INDEX)의 존재 및 우선순위 혹은 FROM절에서의 TABLE 지정 순서에 따라 영향 받는다.
쿼리 튜닝하기
인덱스
- 인덱스 컬럼 가공하지 않기
- 인덱스 컬럼을 가공하지 않아야, 리프블록에서 스캔 시작점을 찾아 거기서부터 스캔하다가 중간에 멈출 수 있음
- 인덱스 순서 고려하기
- 인덱스는 항상 정렬상태를 유지하므로 조건절에 항상 사용되거나 자주 사용하는 컬럼을 앞쪽에 둔다.
- 인덱스 제대로 사용하는지 확인
- 복합 인덱스 사용시 범위 검색컬럼은 뒤에 위치
- 인덱스 구성 확인하기
## 테이블 / 인덱스 크기 확인 SELECT table_name, table_rows, round(data_length/(1024*1024),2) as 'DATA_SIZE(MB)', round(index_length/(1024*1024),2) as 'INDEX_SIZE(MB)' FROM information_schema.TABLES where table_schema = 'subway'; ## 미사용 인덱스 확인 SELECT * FROM sys.schema_unused_indexes; ## 중복 인덱스 확인 SELECT * FROM sys.schema_redundant_indexes;조인문
- 조인 연결 key들은 양쪽 모두 인덱스를 갖도록
- 만약 한쪽에만 인덱스가 있다면 효율이 떨어지고 인덱스가 있는 테이블이 드라이빙 테이블이 되기 때문
- 조인문 연결시 드라이빙 테이블의 데이터를 많게 하고 드리븐 테이블은 primary key인덱스를 사용하여 드라이빙 테이블 보다 적은 양의 데이터를 랜덤액세스 하도록 하여 테이블 액세스 최소화
- 모수 테이블 크기 줄이기
- 서브쿼리보단 조인문 활용하기
- 대부분 조인문이 서브 쿼리보다 성능이 좋다.
쿼리 최적화 및 인덱스 설계
CREATE INDEX `idx_student_years_coding_hobby` ON `subway`.`programmer` (hobby, student, years_coding); SELECT A.id, A.name, programmer.hobby, programmer.dev_type, programmer.years_coding, programmer.student FROM ( SELECT covid.id, hospital.name, covid.programmer_id FROM covid JOIN hospital ON hospital.id = covid.hospital_id ) A JOIN programmer ON A.programmer_id = programmer.id WHERE programmer.hobby = 'YES' AND (programmer.student LIKE 'YES%' OR programmer.years_coding = '0-2 years') ORDER BY programmer.id ASC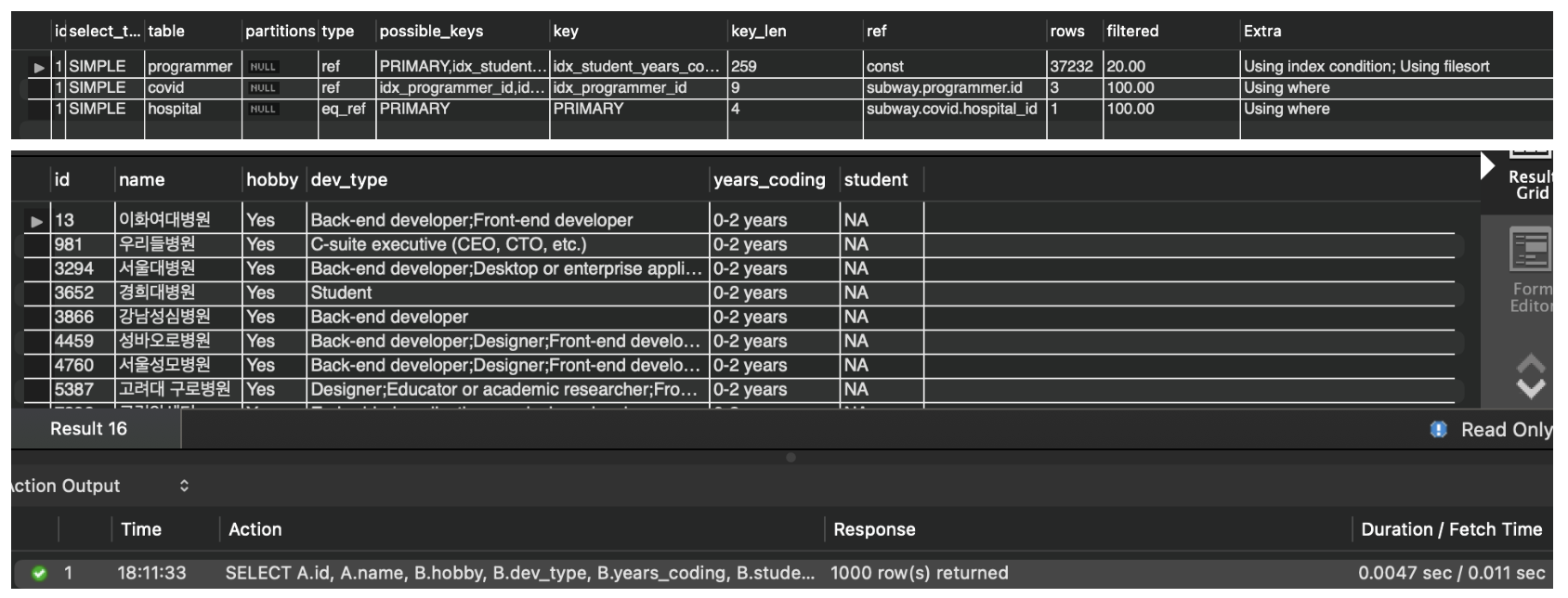

페이징 쿼리를 적용하면 다음과 같이 페치타임을 줄일 수 있다.
CREATE INDEX `idx_student_years_coding_hobby` ON `subway`.`programmer` (hobby, student, years_coding); SELECT A.id, A.name, programmer.hobby, programmer.dev_type, programmer.years_coding, programmer.student FROM ( SELECT covid.id, hospital.name, covid.programmer_id FROM covid JOIN hospital ON hospital.id = covid.hospital_id ) A JOIN programmer ON A.programmer_id = programmer.id WHERE programmer.hobby = 'YES' AND (programmer.student LIKE 'YES%' OR programmer.years_coding = '0-2 years') AND A.id >=20 ORDER BY programmer.id ASC LIMIT 0,20
(참고한 사이트)
NextStep 프로젝트 공방
NEXTSTEP
edu.nextstep.camp
https://nomadlee.com/mysql-explain-sql/
MySQL Explain 실행계획 사용법 및 분석 - Useful Guide
mysql explain, explain 보는법, explain 사용법, select_type type, sub query, where 조건, 서브쿼리, 묵시적 형변환, like 검색, 최적화, type, filtered, type, key_len
nomadlee.com
'데이터베이스' 카테고리의 다른 글
ELK스택 기본사용법 - ② Kibana (0) 2022.10.31 ELK스택 기본사용법 - ① ElasticSearch (0) 2022.10.26 동시성 제어 (0) 2022.08.18 조회 성능 개선하기 ( ③ DB 최적화, Replication ) (0) 2022.04.28 조회 성능 개선하기 ( ① 쿼리 최적화 ) (0) 2022.04.28 - Table Full Scan