-
쿠버네티스 ② 메인 K8s component (2)네트워크 & 인프라 2022. 10. 12. 23:38
지난 글에 이어서 메인 컴포넌트들을 학습하자.
참고한 영상 👇🏼
- 모든 내용은 윗 영상을 캡쳐 및 정리한 내용입니다! 🙌
메인 k8s 컴포넌트
5) Controller



- pod의 개수를 보장 (지휘자 역할)
- 1) ReplicationController


- 요구하는 pod의 개수를 보장하며 파드 집합의 실행을 항상 안정적으로 유지
- 요구하는 개수보다 부족하면 pod 추가, 많으면 최근에 생성된 pod 제거
- 구성
- selector
- replicas
- template

- 2) ReplicaSet


- Replication Controller와 같은 역할(pod의 개수를 보장)
- 단, Replication Controller보다 풍부한 selector를 가짐 ( matchLabels, matchExpressions )
- matchExpressions 연산자
- in : key-value가 일치하는 pod만 연결
- NotIn: key는 일치하고 value는 일치하지 않는 pod에 연결
- Exists : key에 맞는 label의 pod에 연결
- DoesNotExist : key와 다른 label의 pod을 연결
- 3) Deployment

- ReplicaSet을 제어해주는 부모 역할 (ReplicaSet을 컨트롤 하여 pod의 수를 조절)
- Deloyment 정의(kind : Deployment)만 가지고 ReplicaSet 정의를 동작시킬 수도 있음 (거의 동일)



- Rolling Update & Rolling Back 의 목적
- Rolling Update
- pod를 점진적으로 새로운 것으로 업데이트하여 Deployment update가 서비스 중단없이 이루어질 수 있도록 하는 것
- Rolling Update
- 4) DaemonSet
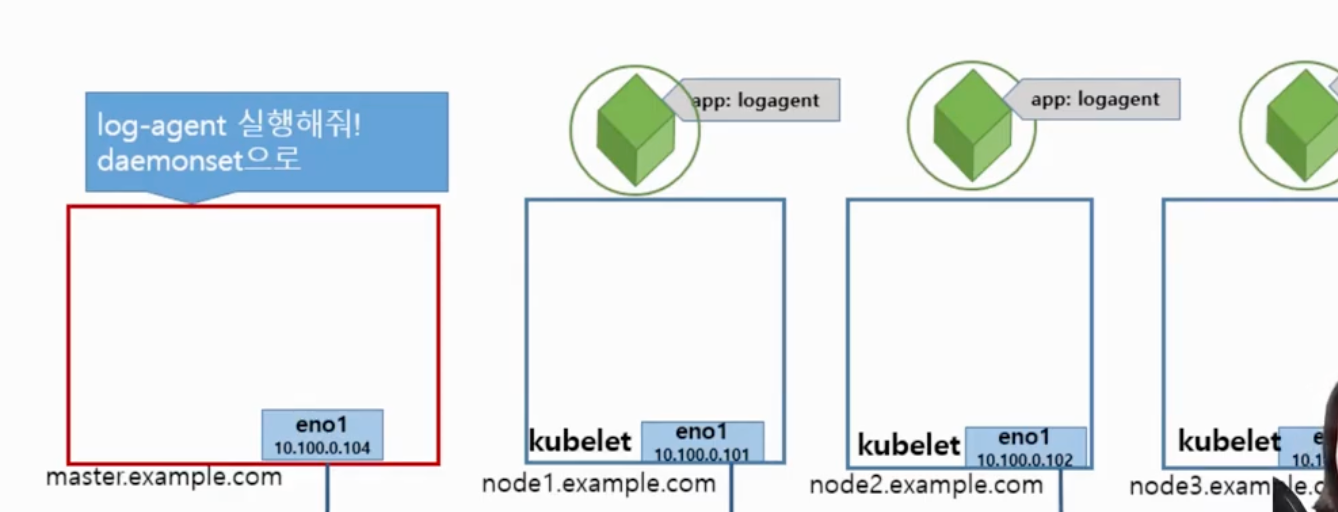

- 전체 노드에서 pod이 한 개씩 실행되도록 보장 (노드당 하나의 어플리케이션이 실행될 수 있도록 보장)
- 하나의 pod(app)이 중단되게 되면 완전히 종료되기를 기다렸다가 그 자리에 하나의 pod을 다시 실행시킴
- 로그 수집기, 모니터링 에이전트와 같은 프로그램 실행시 적용
- kubepod, CLI 등에서는 이미 DaemonSet 사용
- Rolling update 기능도 보유
- 5) StatefulSet


- pod의 상태를 유지해주는 컨트롤러
- pod의 이름
- pod의 볼륨(스토리지)
- 6) Job


- 쿠버네티스는 pod을 running 상태로 유지
- 즉, pod을 정상 상태로 유지
- Batch 처리하는 pod은 작업이 완료되면 종료됨
- Batch 처리에 적합한 컨트롤러로 pod의 성공적인 완료를 보장
- 비정상 종료 시 다시 실행
- 정상 종료 시 완료
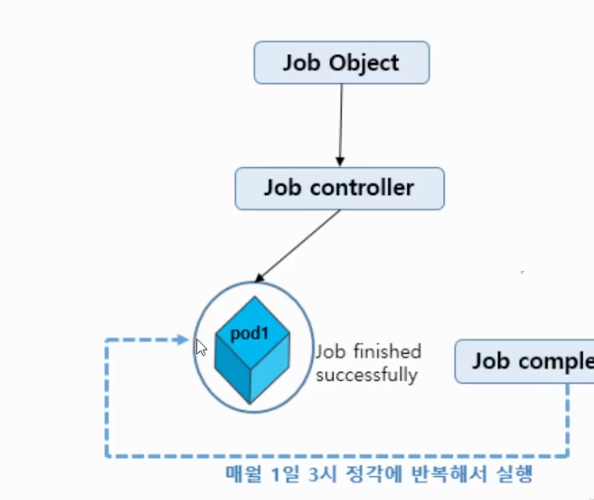
- 6) CronJob


- Job을 제어하여 원하는 시간에 Job의 실행 예약을 지원
- Job 컨트롤러로 실행할 Application pod을 주기적으로 반복해서 실행
- Linux의 cronjob 스케줄링 기능을 Job 컨트롤러에 추가한 API
- successfulJobHistory (default = 3) 을 통해서 성공한 pod의 갯수를 조절할 수 있음
- 반복해서 생성이 된다면 최근 성공한 pod 3개만 남겨두고 이전의 것은 삭제
- 반복해서 실행해야 하는 Job을 운영해야 할 때 사용
- Data Backup
- Send email
- Cleaning tasks
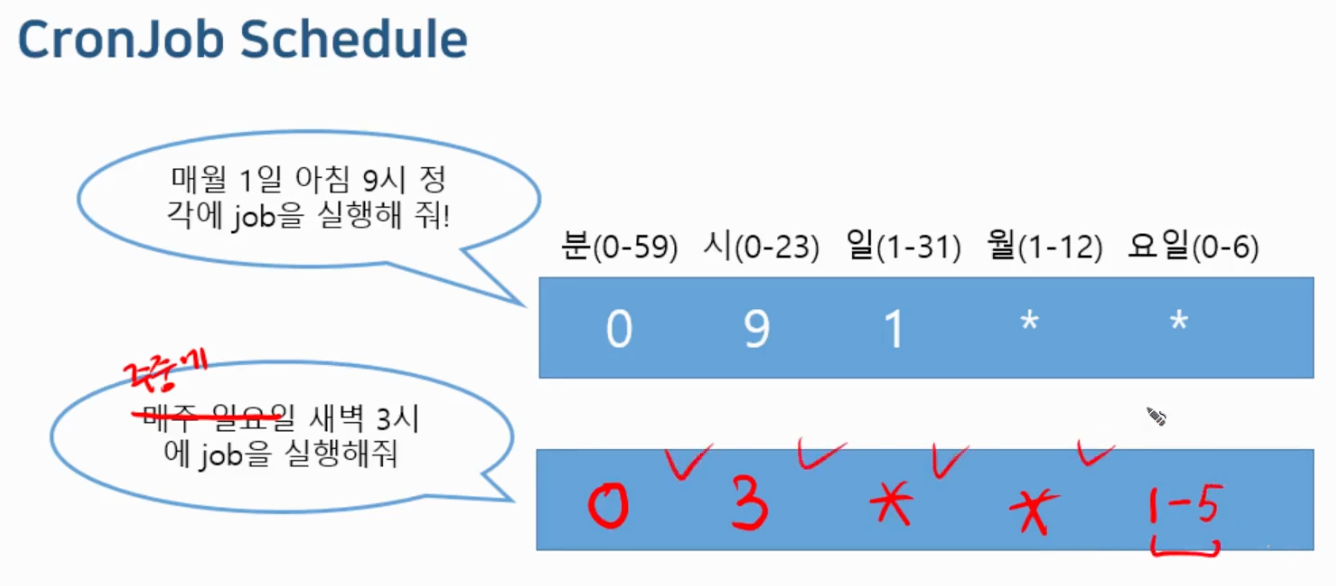
- Cronjob Schedule : “0 3 1 * *”
- Minutes (0 - 59)
- Hours (0 - 23)
- Day of the month (1 - 31)
- Month (1 - 12)
- Day of the week (0 - 6)


6) Deployment 와 StatefulSet

- stateful applications
- databases
- 데이터를 저장하는 어플리케이션
- stateless applications
- 상태를 저장하지 않음
- 모든 요구 사항을 새로운 요청과 같이 받음
- 두가지 경우 모두 컨테이너 specification을 기준으로 pod을 관리하고 같은 방식으로 저장소를 configure
- Deployment : for stateless apps
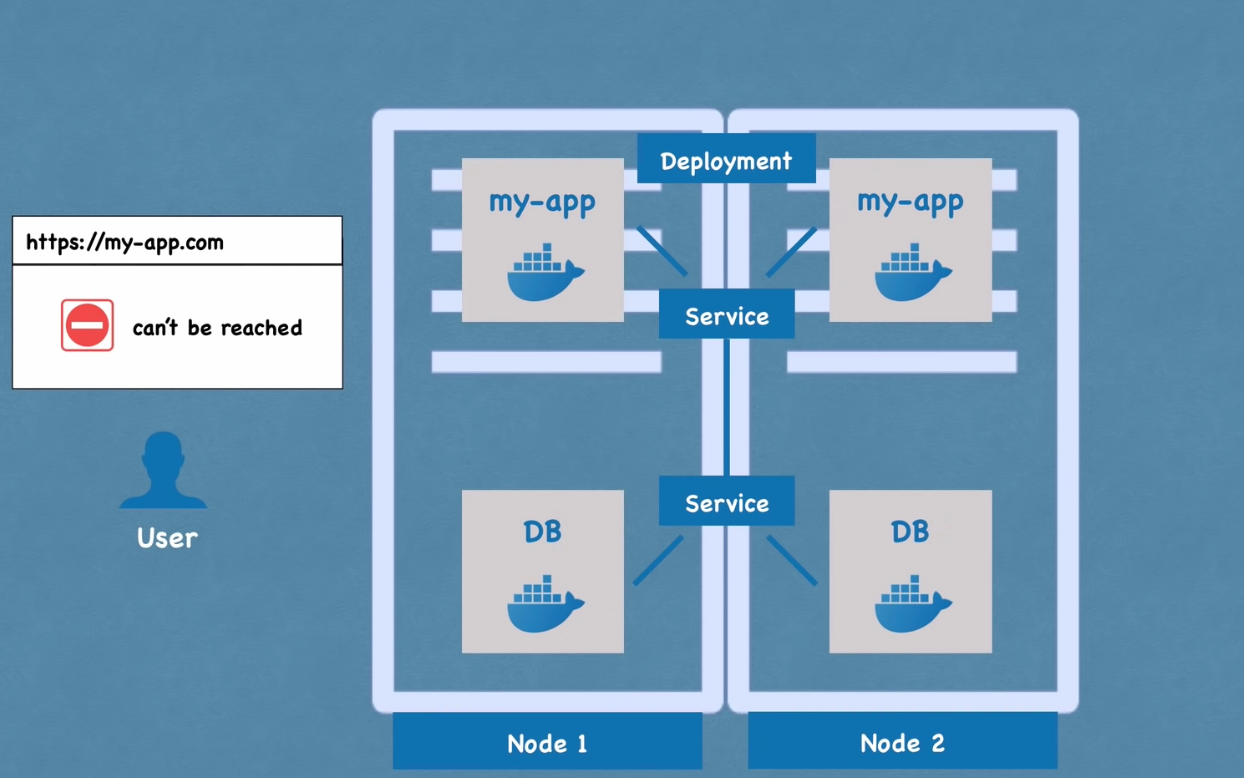
- 특정 pod의 blueprint
- 복사본을 얼마나 만들것인지
- scale up을 얼마나 할 것인지
- pod 의 추상화
- 서비스가 중단되는 것을 방지하기 위해서 pod 이 죽거나 중단된다면 서비스는 또 다른 node안의 pod 에서 정보를 가져옴

- 단, 데이터 불일치 문제로 데이터베이스는 deployment를 통해 복제될 수 없음

- stateless Appliction
- Deployment를 이용하여 배포
- 클러스터 내에 app의 pod을 복제
- 같고 서로 상호교환 가능한 app을 복제
- 랜덤한 순서로 랜덤 해쉬를 가지고 생성됨
- 하나의 서비스가 (SVC) 어떤 pod으로든 로드밸런싱이 가능
- StatefulSet : for stateful 어플리케이션 또는 데이터베이스
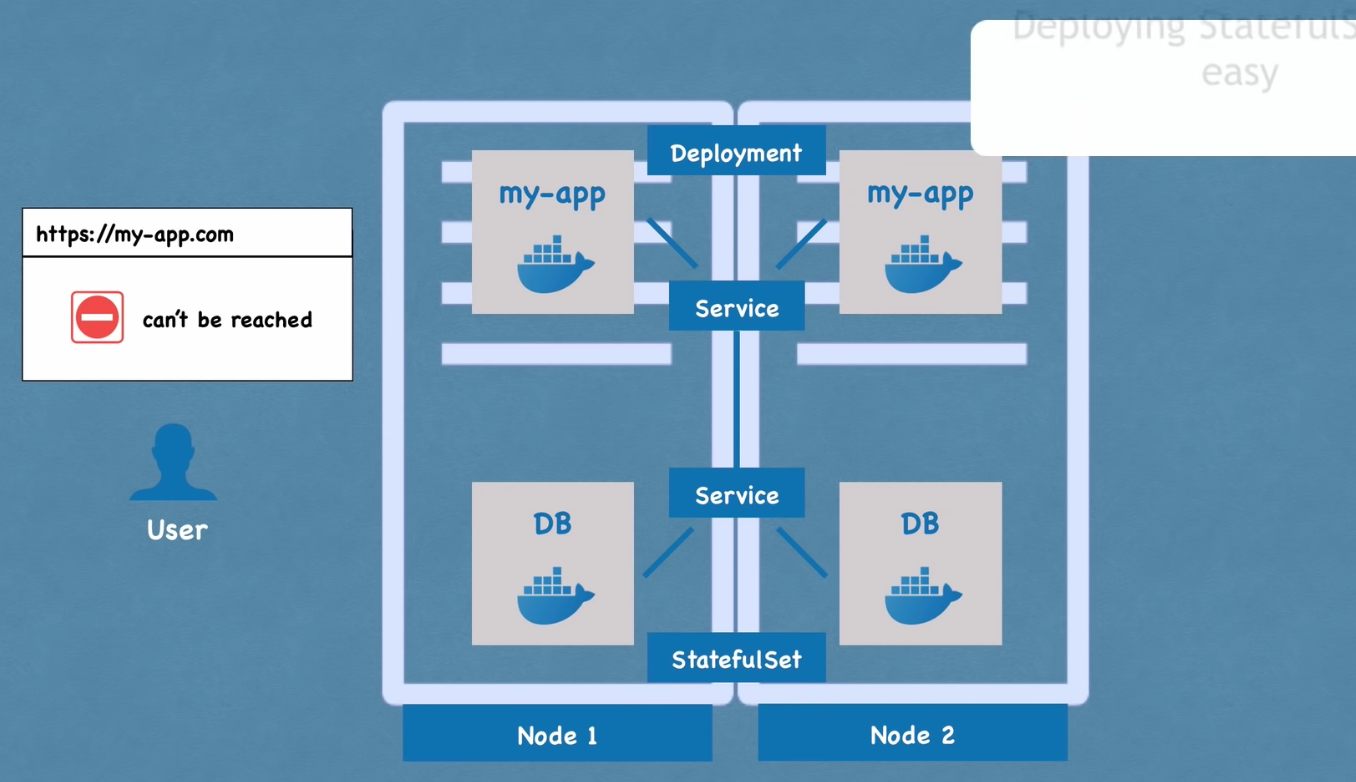
- 상태유지가 필요한 app (ex) mongodb, elasticSearch, mysql 등 )
- deploying statefulSet 은 어려움
- 데이터베이스가 종종 k8s 클러스터 밖에서 호스트 되기 때문
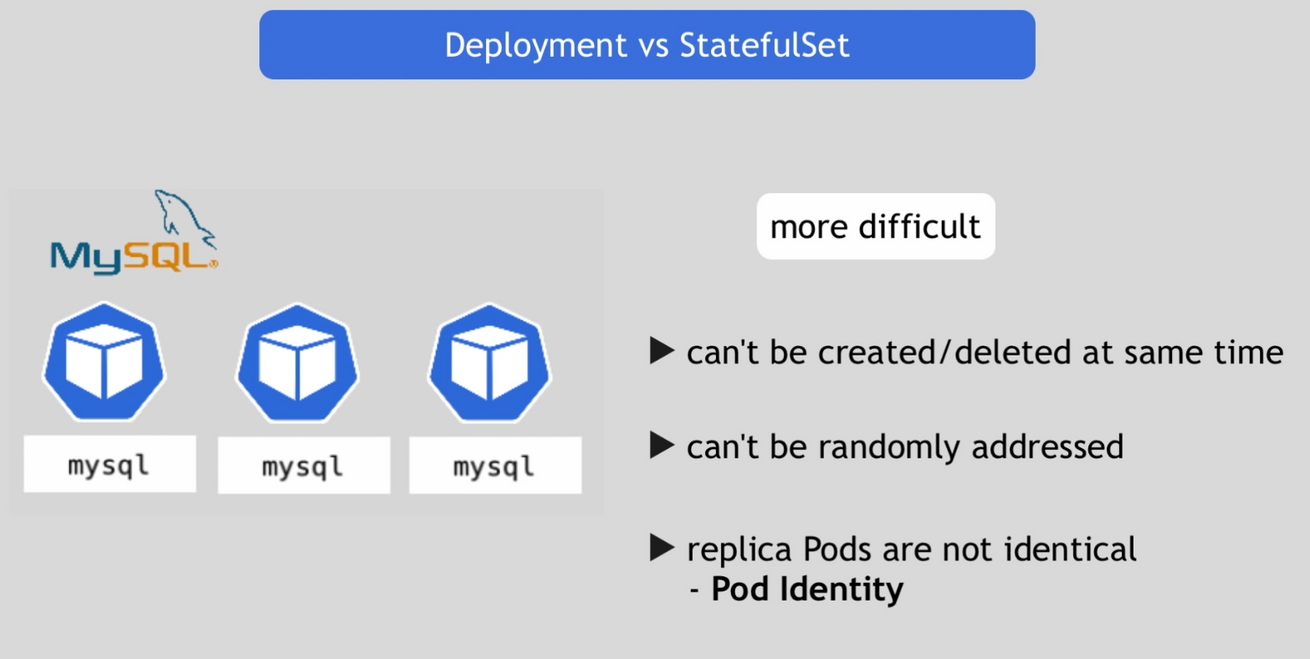
- stateful application
- StatefulSet을 이용하여 배포
- 클러스터 내에 pod을 복제
- stateful application을 복제하는 것이 요구사항이 많아 더욱 어려움
- 동시에 생성되거나 삭제될 수 없음
- 랜덤하게 주소화 될 수 없음
- replica pod이 pod identity와 동일하지 않기 때문
1) Pod Identity

- 각각의 pod이 엄격한 identity를 가짐
- 같은 specification을 갖지만 서로 상호교환 불가
- 어떤 rescheduling을 거쳐도 영구적 identifier -> pod이 중단되어 교체되어도 identity는 동일하게 유지

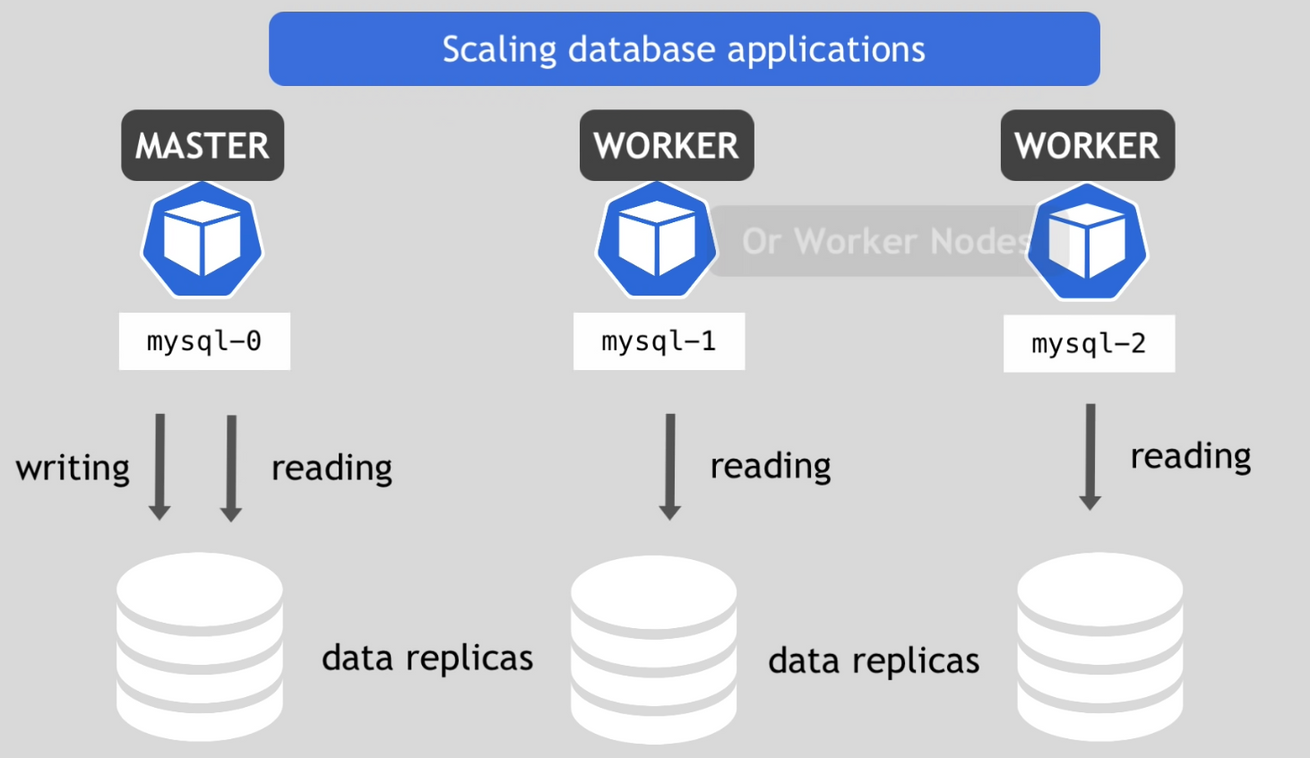
- scaling database applications
- 만약 모든 복제본들이 write / read 모두 수행한다면 데이터 베이스 사이에 데이터 불일치 문제가 발생
- 이를 방지하기 위해 master / worker 구조로 master 는 write / read를 수행하고 worker는 읽기 작업만을 수행하도록 함
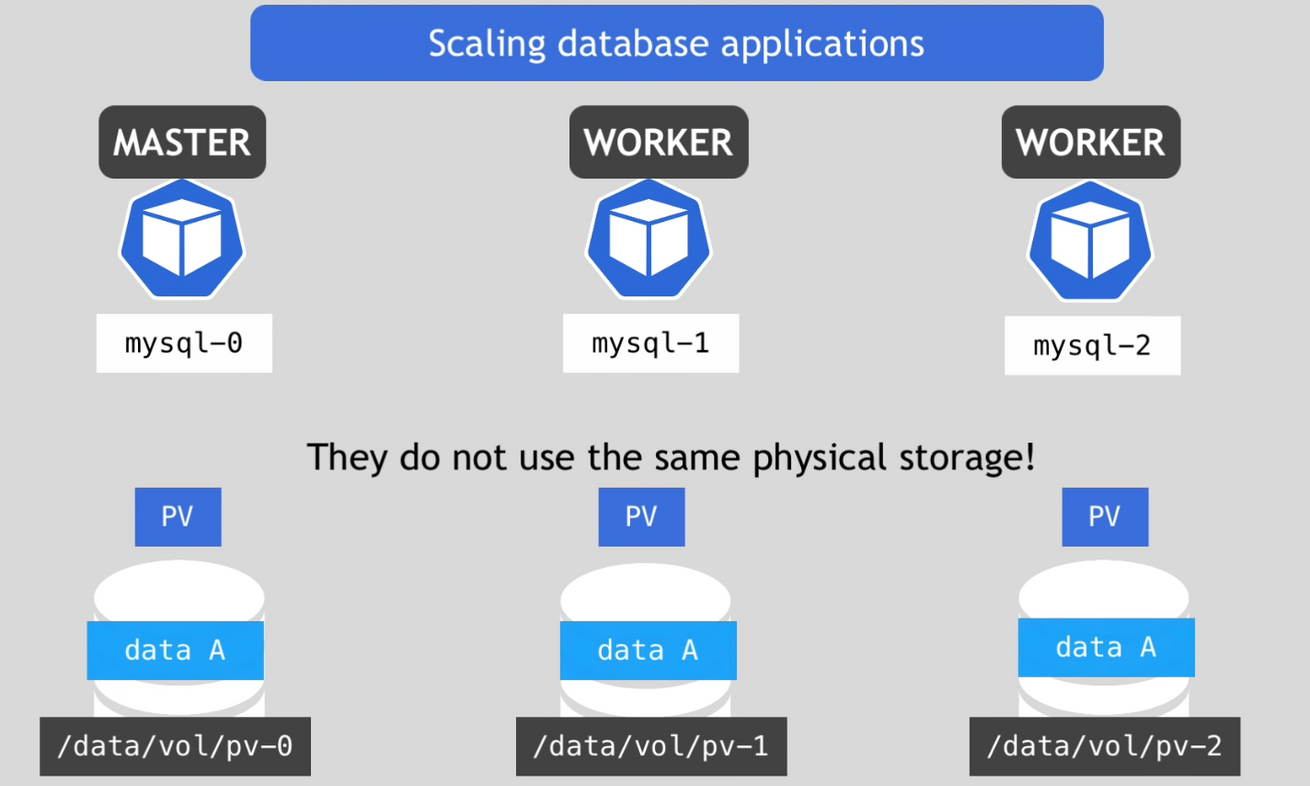
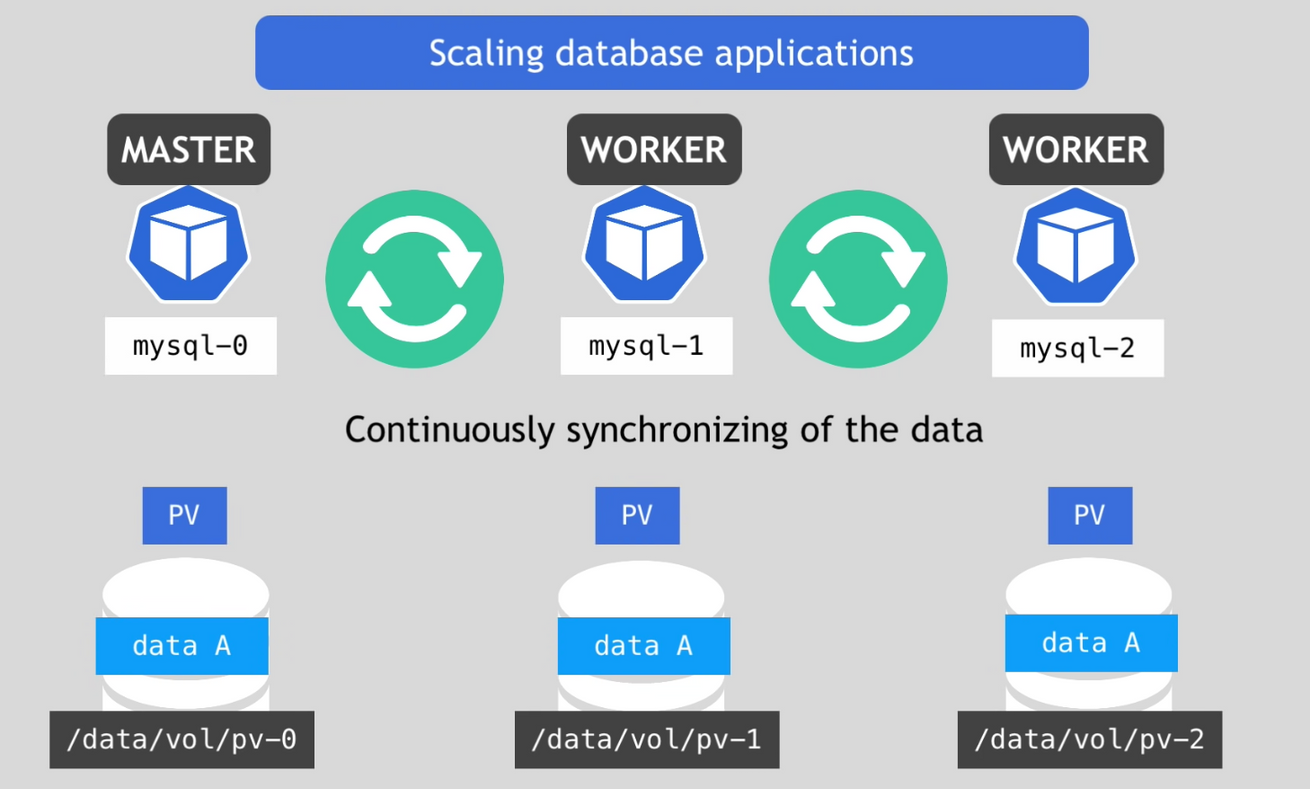
- 하지만 복제본들은 같은 물리 저장소를 사용하지 않으므로 지속적으로 데이터를 동기화 하는 작업이 필요
- worker들은 현재 자신이 최신 상태인지 확인하는 것이 필요


- 만약 새로운 worker를 추가한다고 하면 아무 PV가 아닌 바로 전의 PV을 복제하고 지속적인 동기화를 실행
- 이론적으로는 일시적인 저장소를 사용하는 것이 가능
- 그러나 모든 pod이 중단되거나 죽으면 데이터는 모두 잃어버리게 될 것
- 따라서 PV의 라이프사이클이 다른 컴포넌트의 라이프 사이클에 의존하지 않도록 하는 것이 중요
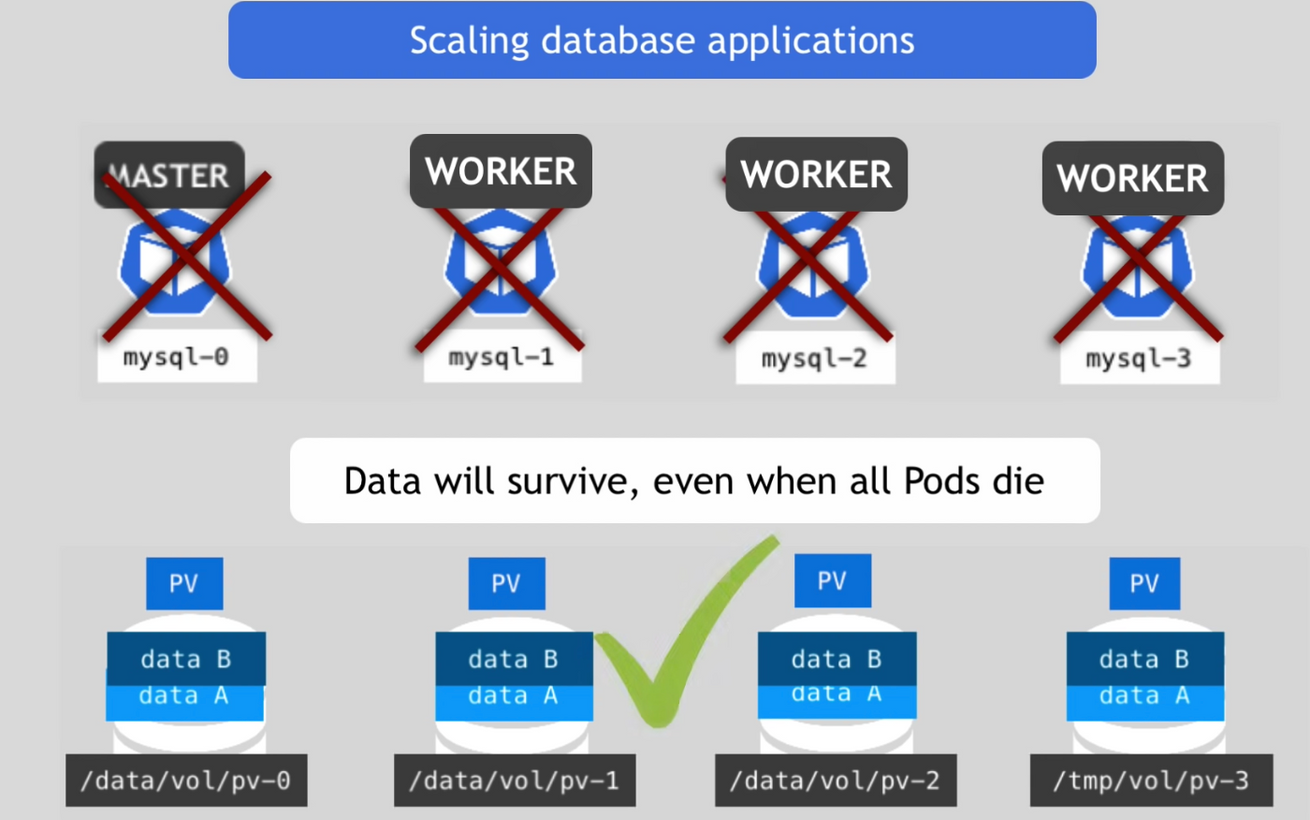
2) pod state
- pod의 모든 상태를 저장하는 개별의 정보 저장소가 존재
- 만약 pod이 중단되면 저장소가 pod의 상태정보를 가지고 있기 때문에 새로운 pod으로 교체 가능
- 이때 데이터가 손실되거나 개별 상태 정보를 잃게 되는 것을 방지하기 위해서 remote 저장소를 사용하는 것이 중요 → 다른 노드를 위해서 이용 가능하게 하는 것이 중요하기 때문
3) statefulSet에서 새로운 pod 생성과 삭제 (replica)
- 이전의 pod이 살아있고 실행되고 있으면 다음 pod은 생성됨
- 삭제는 역순으로 마지막 pod부터 삭제 실행
4) 2 pod endpoints

- 각각의 pod은 service로부터 DNS endpoint 를 가짐
- 로드밸런서 서비스
-
- Deployment와 동일

- 개인의 서비스 이름을 가짐
- ${pod name}.${governing service domain}
- 예상 가능한 pod 이름
- 고정된 개인 DNS 이름
- pod이 재시작 될 때
- Ip 주소는 바뀌지만 이름과 endpoint는 동일하게 남아있음 ⇒ sticky identity
- state와 role을 유지
+) stateful 앱 복제

- 어렵고 복잡
- 쿠버네티스가 이를 도와주지만 해야할 몇가지가 여전히 남아있음
- cloning과 데이터 동기화를 구성해야함
- remote 저장소 사용 가능해야함
- 백업을 관리해야함
- why ?
- stateful 어플리케이션은 컨테이너환경에서 완전하지 않기 때문 (stateless 에 어울림)
+ 쿠버네티스 Label



- 노드를 포함하여 pod, deployment 등 모든 리소스에 할당
- 리소스의 특성을 분류하고 selector를 이용해서 선택
- key-value 한쌍으로 적용
- 연산자 형태의 사용도 가능
- 단, true, false, yes, no 등의 값은 제외
- 모든 노드 들은 두개이상의 label로 구분이 가능

- 워커 노드에 Label 설정 (Node Label)
- 워커 노드의 특성을 Label로 설정
- $ kubectl label nodes <노드이름> <레이블 키> = <레이블 값>
- 노드를 선택해서 pod 배치 가능
- 워커 노드의 특성을 Label로 설정
+ 쿠버네티스 애노테이션

- Label과 동일하게 key-value를 통해 리소스의 특성을 기록
- kubernetes 에게 특정 정보를 전달할 용도
- ex) Deployment의 rolling update 정보 기록
- 관리를 위해 필요한 정보를 기록할 용도
- release, logging, monitoring에 필요한 정보들을 기록
+ 쿠버네티스 레이블을 이용한 Canary Deployment
- 코드를 배포(업데이트)하는 방법
- 블루 그린 업데이트
- 카나리 업데이트
- 롤링 업데이트
- 카나리 배포
- 기존 버전을 유지한 채로 일부 버전만 신규 버전으로 올려서 신규 버전에 버그나 이상은 없는지 확인

'네트워크 & 인프라' 카테고리의 다른 글
쿠버네티스 ④ Minikube 와 Kubectl, K8s YAML configuration File (0) 2022.10.12 쿠버네티스 ③ 기본 Architecture (0) 2022.10.12 쿠버네티스 ① 메인 K8s component (1) (1) 2022.10.08 gRPC ③ gRPC + 스프링부트 프로젝트 구성해보기 (0) 2022.10.05 gRPC ② gRPC + 자바 프로젝트 구성해보기 (1) 2022.10.05