-
아파치 카프카네트워크 & 인프라 2022. 10. 26. 10:50
EDA를 배우면서 카프카에 대해서 알게 되었고,
유튜브를 찾아보니 다음의 플레이리스트 강의가 있어서 아주 간단하게 기본 개념만이라도 학습해보았다!
정리한 자료 및 사진은 모두 영상의 내용을 참고하였다!
↓
https://www.youtube.com/watch?v=7QfEpRTRdIQ&list=PL3Re5Ri5rZmkY46j6WcJXQYRlDRZSUQ1j&index=2
카프카를 쓰는 이유
Apache Kafka를 사용하여 EDA 적용하기
안녕하세요, 여기어때의 결제정산개발팀에서 예약 개발 업무를 맡고 있는 paori 입니다.
techblog.gccompany.co.kr
카프카는 발행 - 구독(pub - sub) 모델의 메세지 큐를 가진 이벤트 스트리밍 플랫폼으로 분산 환경에서 대규모 메세지를 안정적으로 전송, 수집 및 활용할 수 있기 때문에 사용된다.
- high throughput message capacity
- 짧은시간 안에 많은 양의 데이터를 컨슈머까지 전달
- 파티션을 통한 분산처리 / 이에 따른 컨슈머 병렬처리 가능
- scalability 와 fault tolerance
- 확장성이 뛰어남
- 이미 사용되고 있는 브로커가 존재해도 신규 브로커 서버를 통한 확장이 가능
- 브로커가 죽더라도 이미 Replica를 통해 복제된 데이터는 안전 복구가 가능
- undeleted log
- 카프카 토픽에 들어간 데이터는 컨슈머가 데이터를 가져가도 데이터가 사라지지 않음
- 컨슈머의 그룹아이디만 다르다면 동일한 데이터도 각각 다른 형태의 처리가 가능
브로커 (Broker)
- 실행되고 있는 카프카 어플리케이션이 설치된 노드나 서버를 말함
- 2대 이상의 브로커로 클러스터 구성
- 주키퍼와 연동
- 주키퍼
- 메타데이터(브로커 id, 컨트롤러 id 등) 저장
- 주키퍼
- n개 브로커 중 1대는 컨트롤러 기능 수행
- 컨트롤러
- 각 브로커에게 담당파티션 할당 수행
- 브로커 정상 동작 모니터링 관리
- 컨트롤러 담당은 주키퍼에 저장
- 컨트롤러
토픽 (Topic)

- 메세지 분류 단위로 n개의 파티션 할당이 가능
- 각 파티션마다 고유한 offset을 가짐
- 메세지 처리 순서는 파티션 별로 유지 및 관리
- 카프카는 토픽을 여러개 생성이 가능
- 토픽은 목적에 따라 이름을 가질 수 있음
1) 파티션이 1개인 경우
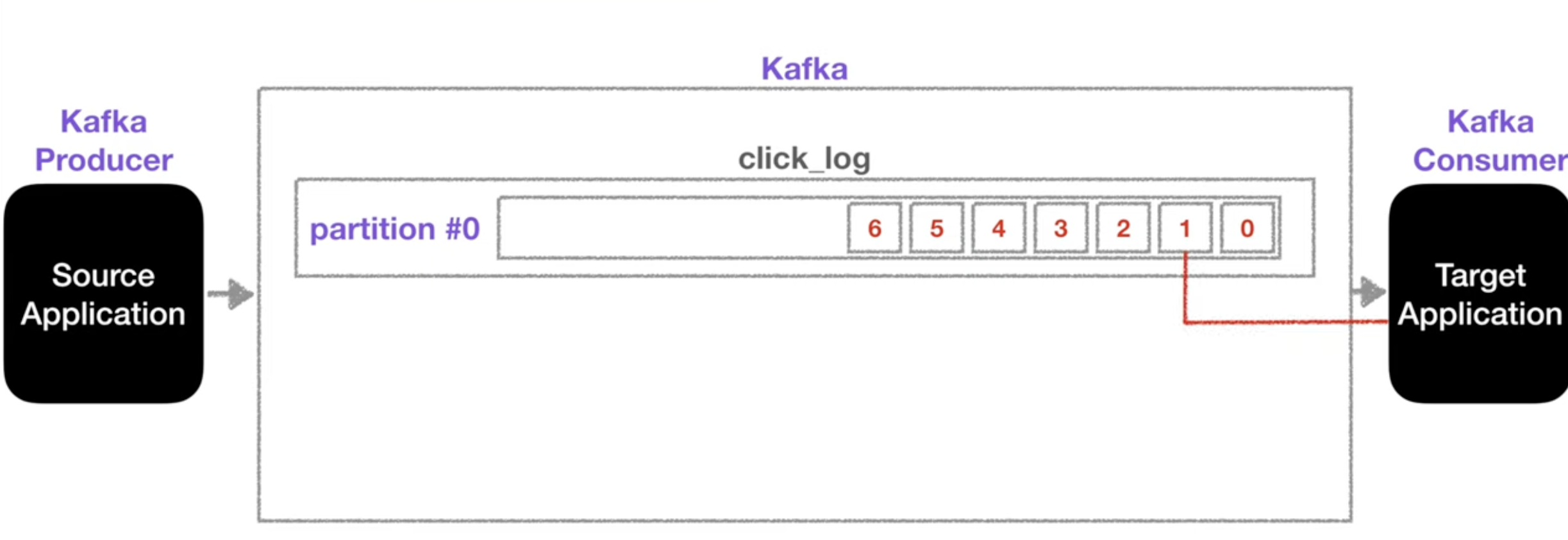
- 하나의 토픽은 여러개의 파티션으로 구성될 수 있음
- 첫번째 파티션 번호는 0번부터 시작
- 큐처럼 동작하여 해당 로그를 쌓고 타겟 (컨슈머)어플리케이션은 가장 오래된 로그부터 사용
- 더이상 데이터가 들어오지 않으면 컨슈머는 또다른 데이터가 들어올 때까지 기다림

- consumer가 데이터를 가져가도 파티션에서 데이터가 삭제되지 않음
- 남은 데이터는 새로운 컨슈머가 다시 처음부터 가져갈 수 있음

- 컨슈머 그룹이 다른 경우에는 auto.offset.reset = earliest 옵션을 주어야 함.
2) 파티션이 2개 이상인 경우

- 프로듀서가 키를 이용하여 파티션을 구분하여 데이터를 넣음
- 만약 키가 null이고 기본 파티션을 사용하는 경우에 RR(라운드 로빈)방식으로 할당됨
- 키가 있고 기본 파티셔너를 사용하는 경우 키의 해시 값을 구하고 특정 파티션에 할당됨
- 파티션을 늘리는 것은 주의!
- 파티션을 늘리는 것은 가능하지만 줄이는 것은 불가능하기 때문
- 파티션 늘림 = 컨슈머 분산 = 분산 데이터 처리 가능
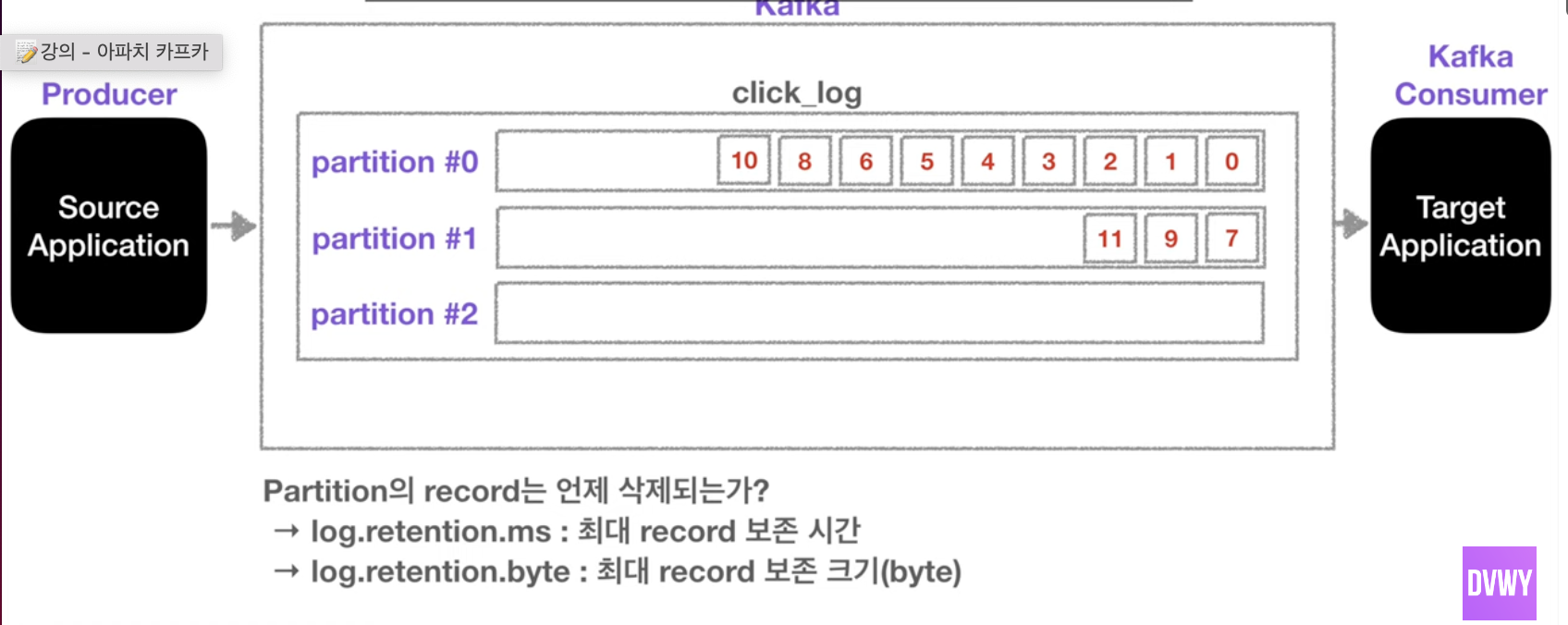
- 파티션 레코드의 기간은 옵션에 따라 다름
레코드 (Record)

- 객체를 프로듀서에서 컨슈머로 전달하기 위해 kafka 내부에 바이트 형태로 저장할 수 있도록 직렬화 / 역직렬화 하여 사용
- 기본 제공 직렬화 class : StringSerializer, ShortSerializer 등
- 커스텀 직렬화 class를 통해 Custom Object 직렬화 / 역직렬화 가능
프로듀서 (Producer)
- 데이터를 카프카에 생성하는 역할
- topic에 해당하는 메세지를 생성
- 특정 topic으로 데이터를 publish
- kafka broker로 데이터 전송시 처리 실패를 확인할 수 있고 / 재시도도 가능
- 카프카는 maven이나 gradle 디펜던시로 org.apache.kafka 를 추가하여 사용 가능
- 추가할 때에는 브로커 버전과 클라이언트 버전의 하위호환성이 가능한지 확인 후 사용해야 함
- 예시로 확인하기

- 카프카를 사용할 때 프로듀서에 적어도 2개 이상의 브로커 정보(여기서 bootstrap.servers, localhost:9091)를 넣어 하나의 브로커가 고장나도 서비스가 중단되지 않도록 하는 것이 중요
- <key - value> 형태 → 키는 메세지를 보내면, 토픽의 파티션이 지정될때 사용됨

키를 넣지 않았을 때 (RR) 
키를 넣었을 때 (해당 키에 맞는 파티션에 배정됨) - 파티셔너 (Partitioner)

- 파티셔너는 메시지니 토픽의 어떤 파티션에 넣을지 결정하는 역할
- 레코드에 포함된 메세지 키, 값에 따라서 파티션 위치 결정
- 파티셔너를 따로 설정하지 않을 경우 UniformStickyPartitioner로 설정됨
- 메세지 키가 있을 때
- 파티셔너에 의해 특정 해시값이 생성됨
- 이 해시값을 기준으로 파티션이 결정됨
- 동일 키를 가진 레코드들은 항상 동일 파티션으로 배정됨 (순서를 지킨 데이터 처리가 가능)
- 메세지 키가 없을 때
- 배치 단위로 라운드 로빈 형식으로 들어가게 됨
- 커스텀 파티셔너를 생성하는 것도 가능
- partitioner 인터페이스를 사용해서 생성이 가능
- 사용 시기
- ex) VIP 고객을 위해서 데이터 처리가 빨라야 하는 경우
- 데이터 처리량을 몰아서 해결
- 우선순위 큐처럼 동작
Replication
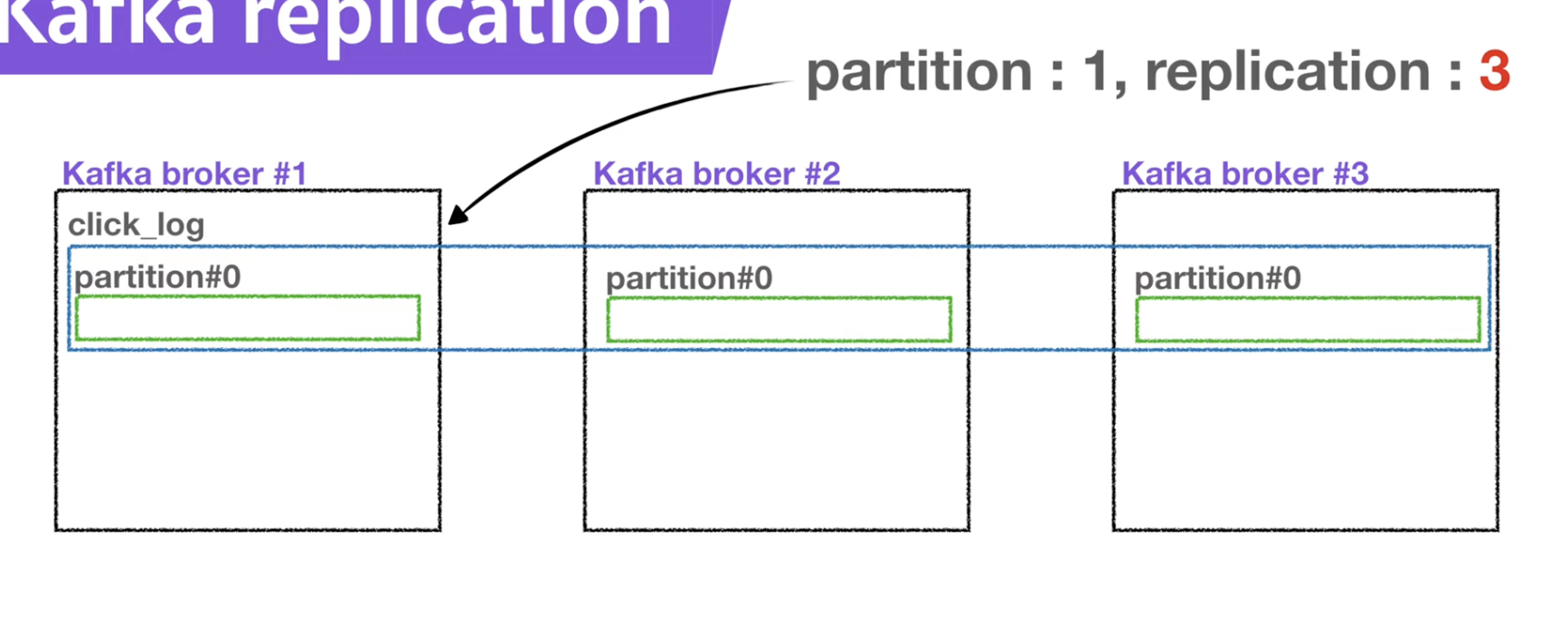
- 만약 partition 1, replication1이면 파티션이 1개만 존재하는 것이고, partition1, replication2 라면 원본 1개와 복제본 1개 총 2개가 존재한다는 것을 나타냄
- 사진으로 보면 partition1, replication3으로 원본 1개와 복제본 2개 총 3개가 존재하는 것을 확인할 수 있음
- 단, 여기서 replciation의 갯수가 broker의 갯수보다 많을 수는 없음
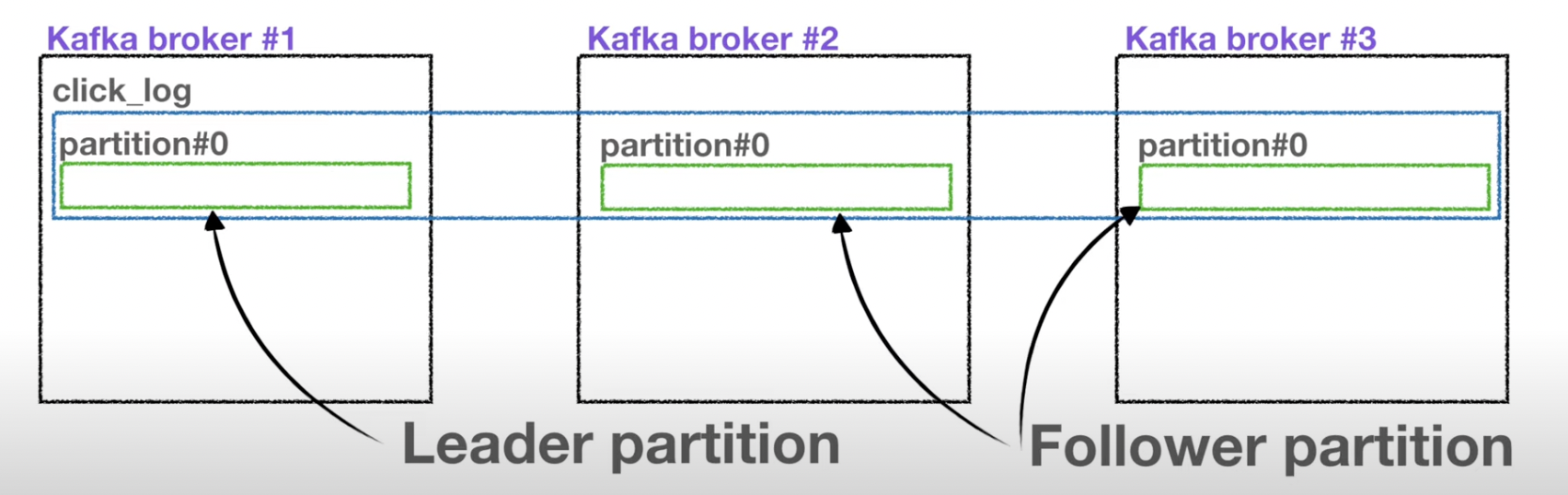
- Leader partition : 원본 파티션
- Follower partition : 복제본 파티션

- ISR(In Sync Replica) : leader partition = follower partition
- 즉, 특정 파티션의 리더, 팔로워의 레코드가 모두 복제되어 sync가 맞는 상태
- ISR이 아닌 상태에서 장애가 발생하면 unclean.leader.election.enable
- 사용 이유?
- replication은 파티션의 고 가용성을 위해 사용
- 만약 partition1, replication1인 브로커에 고장이 난다면, 더이상 해당 파티션은 복구가 불가능하지만, replication이 2인 경우에는 원본 파티션의 브로커가 고장나도 나머지 복제본이 leader partition의 역할을 승계하여 사용이 가능
- 단, replication의 양이 많아지면 브로커의 리소스 사용량이 늘어나게 되므로 카프카에 들어오는 데이터양과 retention data (저장시간)을 잘 생각해서 replication 갯수를 정하는 것이 좋다.
- 프로듀서가 토픽의 파티션에 데이터를 전달할 때 받는 것이 leader partition이다.
- ack을 통해서 고가용성을 유지할 수 있음

- 만약 ack = 0 이라면 요청을 보내고 응답값을 받지 않아 데이터 유실 유무를 확인하지 않는다.
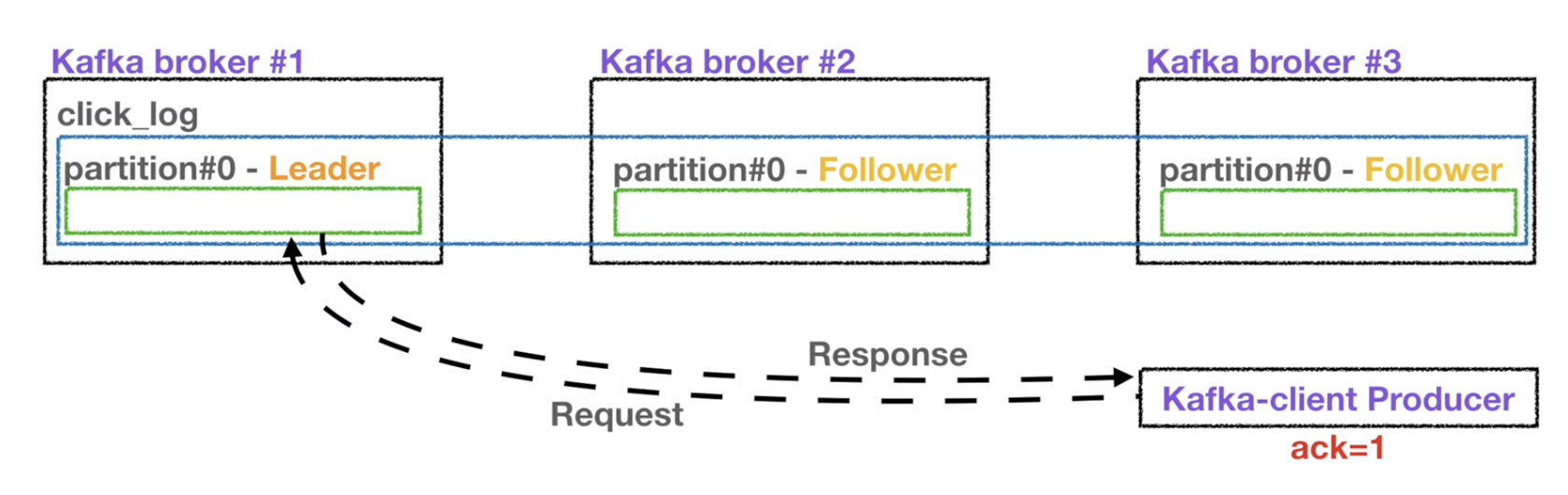
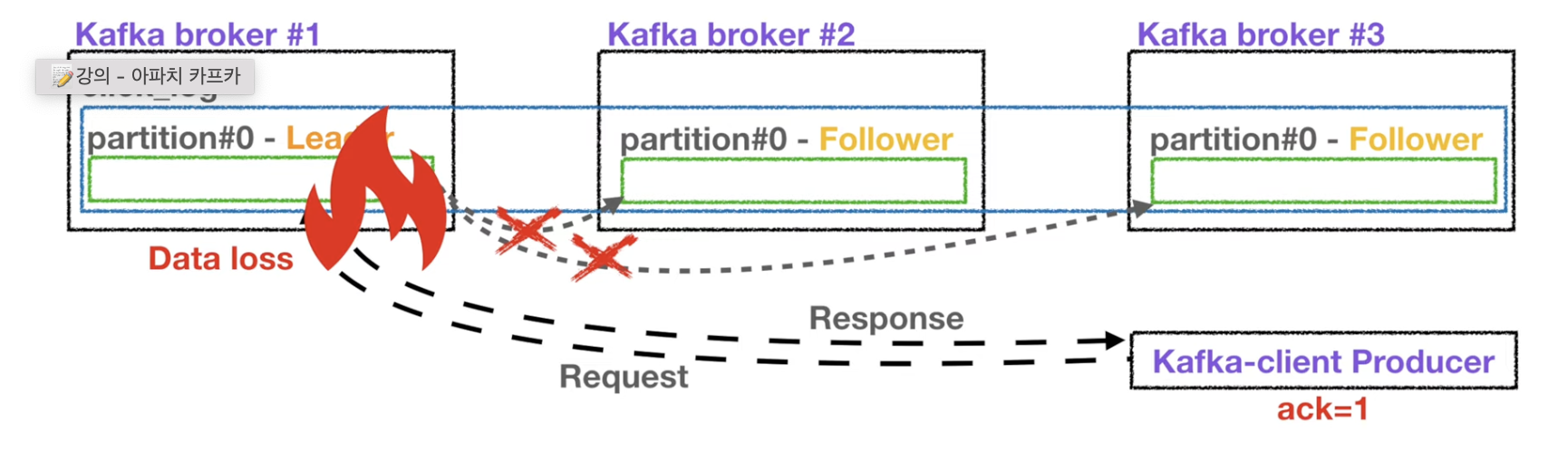
- ack = 1 이라면 리더 파티션에는 요청을 보내고 응답값을 확인하지만 복제본들에 대해서는 응답값을 확인하지 않으므로 해당 요청에서 데이터 유실이 일어나도 알 수 없음

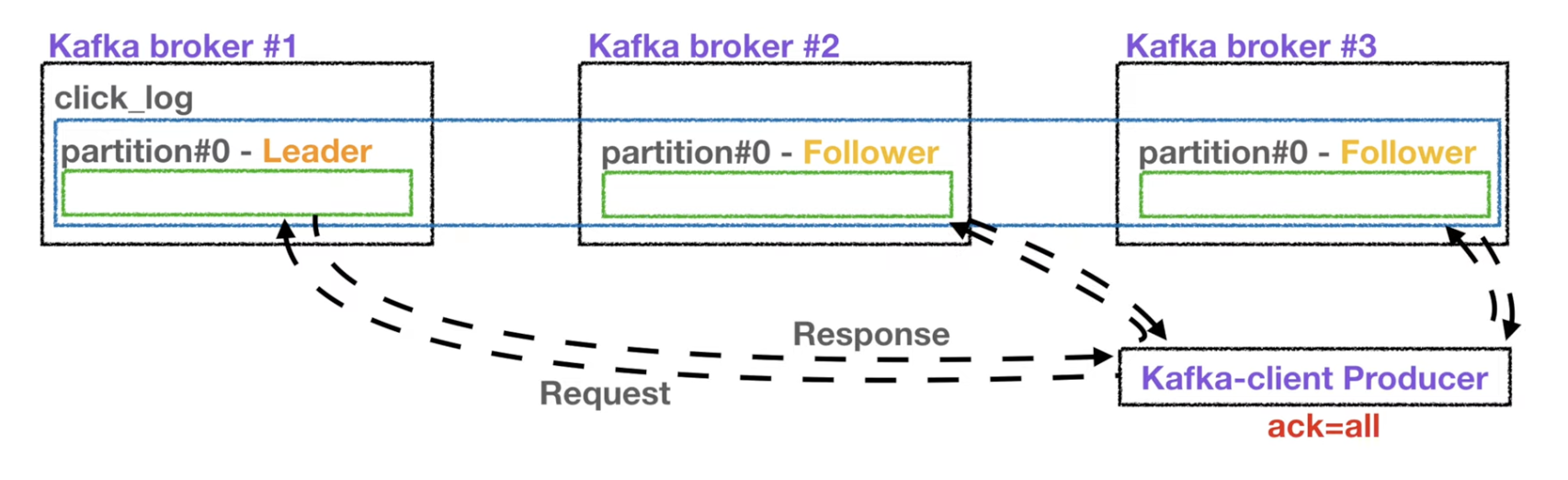
- ack = all 옵션에서는 리더파티션과 복제본 모두 응답값을 확인하지만 이 과정이 속도가 현저히 느리다는 단점이 있다.
컨슈머 (Consumer)

- topic의 partition으로 부터 데이터 polling
- 토픽 내부의 파티션에서 메세지 가져오기
- 이후 특정 DB에 저장하거나 또다른 파이프라인에 전달 가능
- polling : 컨슈머가 파티션에 저장된 데이터를 가져옴
- partition offset 위치 기록(commit)
- offset : 파티션에 있는 데이터 번호
- consumer group을 통해 병렬 처리
- 파티션 개수에 따라 컨슈머를 여러개 만들어 병렬처리 → 빠른 처리가 가능
- 예시로 확인하기
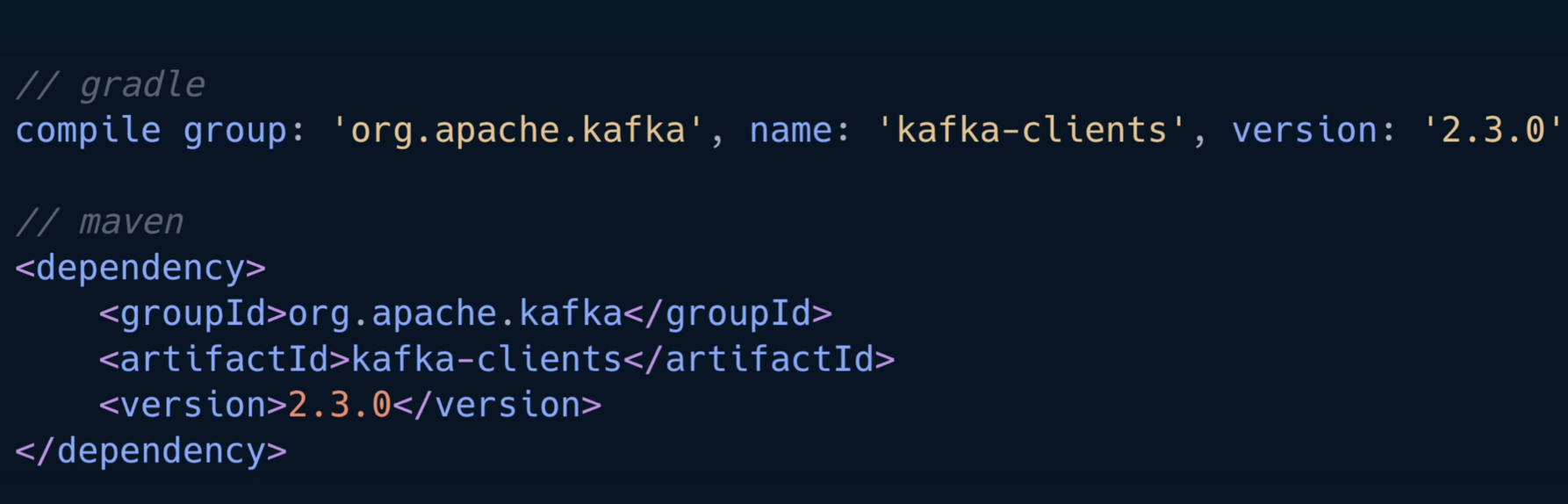
- 라이브러리 추가 (클라이언트와 브로커 버전 확인 필수)
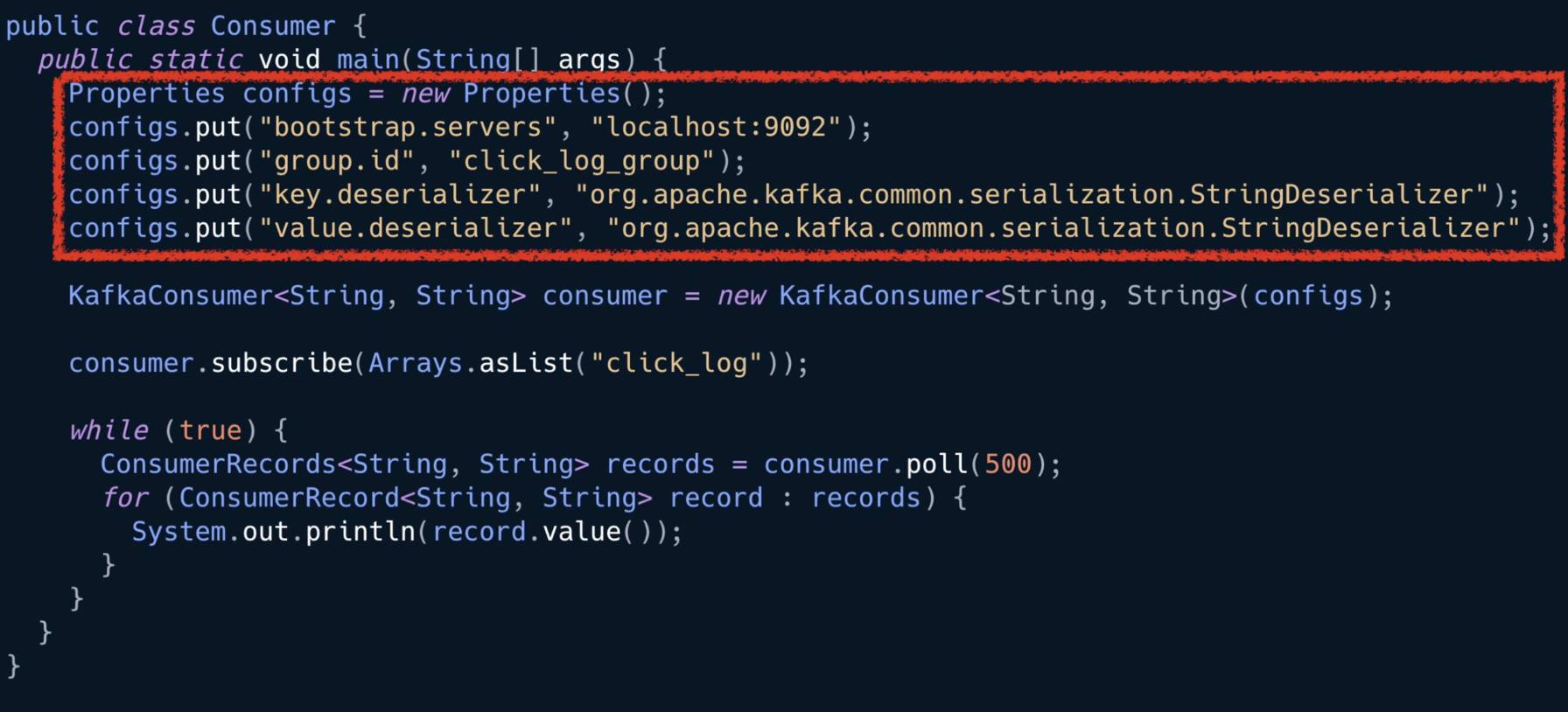
- 자바 프로퍼티 설정을 통해 브로커, 컨슈머 설정
- 데이터를 읽어오는 polling loop
- 일정 시간동안 브로커로부터 연속적으로 컨슈머가 허락하는 한 많은 데이터를 읽음
- 컨슈머 API의 핵심 로직
- records 를 for 루프에서 반복처리 하면서 실질적으로 처리하는 데이터를 가져오도록 한다

- 일부 데이터만 가져오고 싶다면 assign 메서드를 사용한다.

- 프로듀서와 같이 key가 null인 경우 두개의 파티션이 있다면 라운드로빈으로 넣는다.
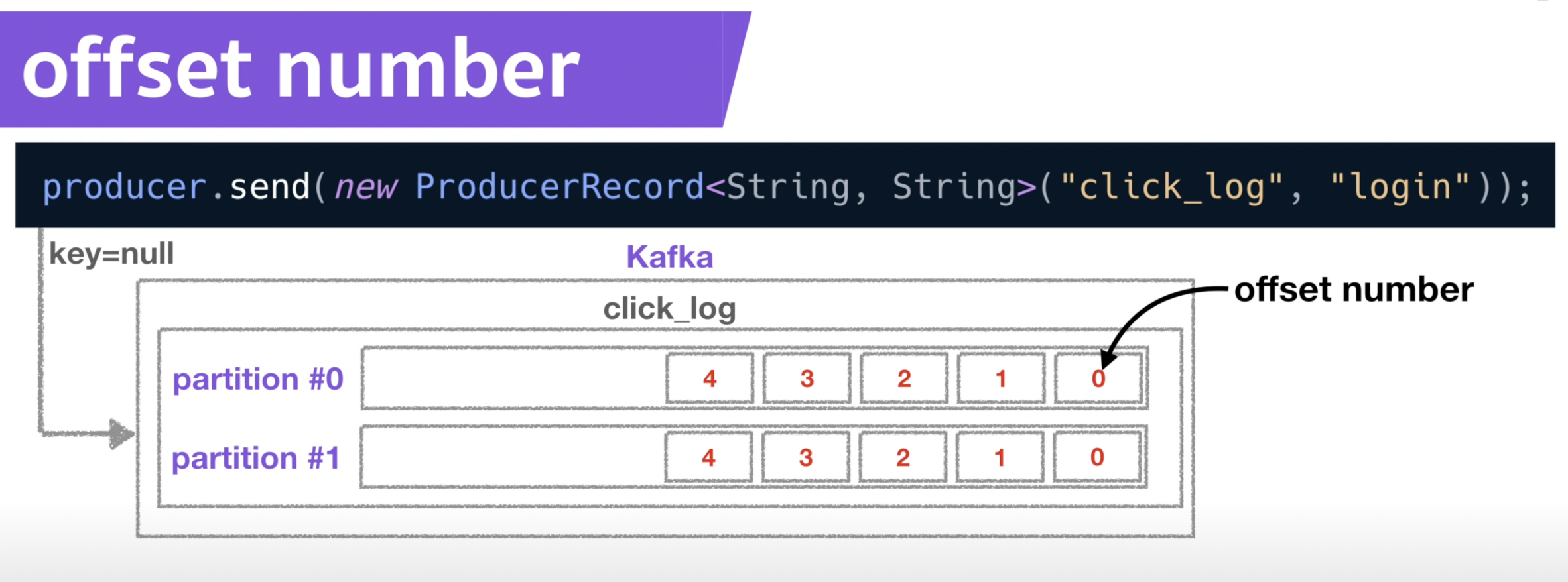
- offset number
- 각각 데이터의 고유한 번호
- 컨슈머가 데이터를 어느지점까지 읽었는지 표시
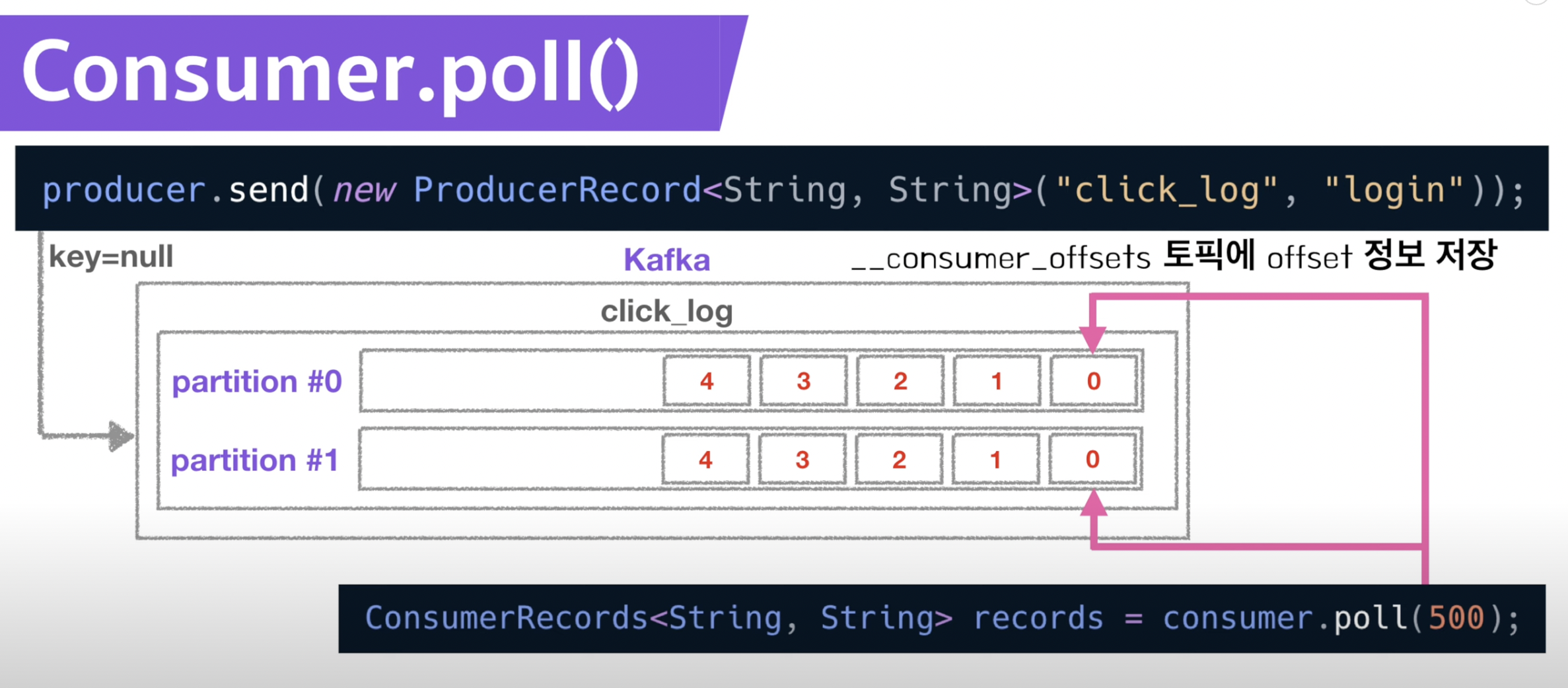
- 컨슈머가 데이터를 읽기 시작하면 offset을 commit
- 이때 가져간 내용에 대한 정보는 카프카 __consumer_offsets 토픽에 저장
- 이를 통해 만약 컨슈머가 멈추는 사건이 발생하여도 어디까지 읽었는지 저장해두었기 때문에 offset을 이용해서 복구가 가능
- 시작 ~ offset까지 다시 읽음 → 고가용성


- 병렬처리를 위해 컨슈머의 개수는 파티션 개수보다 작거나 같아야 한다.

- 다른 컨슈머 그룹에 속한 컨슈머는 서로의 동작에 대해 영향을 미치지 않음
- 컨슈머 오프셋 토픽에는 컨슈머 그룹별 및 토픽별로 offset을 나누어 저장하기 때문
Lag

- 만약 컨슈머의 속도 지연이나 다른 외부 요인으로 프로듀서가 생성하는 속도와 컨슈머가 소비하는 속도가 다르다면?
- 두 오프셋 간의 차이가 발생 → kafka consumer lag
- 프로듀서 오프셋과 컨슈머 오프셋간의 차이
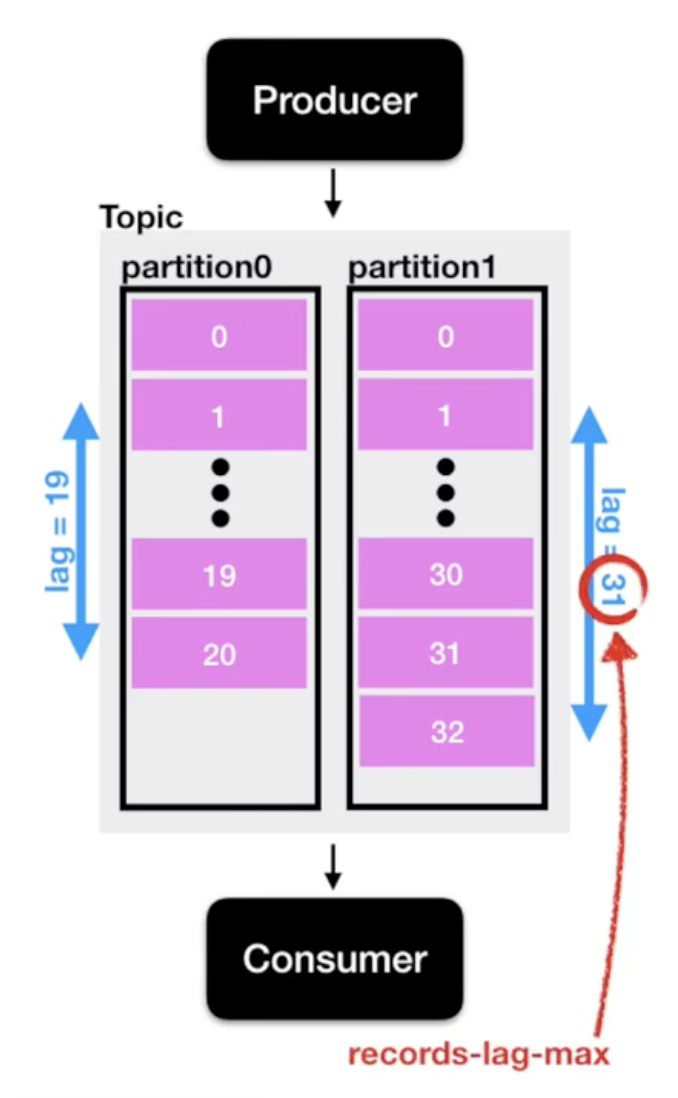
- records-lag-max : 한 토픽에 두개 이상의 파티션이 존재하고 각각의 lag(여러개의 lag)이 존재할 때 가장 큰 lag
- 프로듀서의 오프셋과 컨슈머의 오프셋간의 차이가 클때, 즉, 컨슈머의 소비량이 따라가지 못하는 경우(지연)가 발생할때 모니터링이 필요
- 실시간 감시 → influxDB, elasticSearch + grafana 대시보드 사용
- 컨슈머로직 단에서 lag 수집하는 것 = 컨슈머 상태에 디펜던시가 걸릴 수 있음
- 컨슈머가 비 정상적으로 종료되면 더이상 컨슈머는 lag 정보를 보낼 수 없어 더이상 lag 측정이 불가해짐
- 추가적으로 컨슈머가 개발될 때 마다 해당 컨슈머에 lag 정보를 특정 저장소에 저장할 수 있도록 로직을 개발해야 함.
- 해결책 lag 모니터링 => Burrow
- golang으로 작성되어있음
- 컨슈머 lag 모니터링을 도와주는 독립적 어플리케이션
- 장점
- 멀티 카프카 클러스터 지원
- sliding window를 통한 consumer의 status 확인
- 컨슈머의 상태를 ERROR, WARNING, OK로 표현
- 데이터 양이 일시적으로 많아지고 있어서 컨슈머 offset이 증가되고 있으면 WARNING으로 정의됨
- 데이터 양이 많아지고 있는데 컨슈머가 데이터를 가져가지 않으면 ERROR로 정의하여 실제로 컨슈머가 문제가 있는지 없는지 판단
- HTTP api 제공
- 다양한 추가 생태계 구축이 가능
- 실시간 감시 → influxDB, elasticSearch + grafana 대시보드 사용
Kafka Streams

- 데이터를 변환하기 위한 목적으로 사용하는 API
- 토픽에 있는 데이터를 낮은 지연과 함께 빠른 속도로 데이터 처리가 가능
- 스트림 프로세싱을 지원하기 위한 다양한 기능을 제공
- stateful 또는 stateless 와 같이 상태기반 스트림 처리 가능
- Stream api와 DSL(Domain Specific Language)를 동시 지원
- Exactly-once 처리, 고 가용성 특징
- Kafka security(acl, sasl 등) 완벽 지원
- 스트림 처리를 위한 별도 클러스터(ex. yarn 등) 불필요
Kafka Connect

- 많은 경우 Kafka client로 Kafka로 데이터를 넣는 코드를 작성할 때도 있지만, Kafka connect를 통해 데이터를 Import / Export 할 수 있음
- 데이터 파이프라인을 반복적으로 수행할때 사용됨
- connector를 동작하게끔 실행해주는 프로세스
- 코드 없이 configuration으로 데이터를 이동 시키는 것이 목적
- Standalone mode, distribution mode 지원
- REST api interface를 통해 제어 (post, get 등의 메서드)
- Stream 또는 Batch 형태로 데이터 전송 가능
- 커스텀 connector를 통한 다양한 plugin 제공(ex) File, S3, Hive, MySQL 등)
- 커넥터 (Connector)
- 싱크커넥터
- 데이터를 싱크
- 특정 토픽에 있는 데이터를 mySQL, ES, 오라클 등으로 특정 저장소에 저장하는 역할
- 즉, 컨슈머와 같은 역할 수행
- 소스 커넥터
- 데이터베이스로 부터 데이터를 가져와서 토픽에 넣는 역할
- 즉, 프로듀서와 같은 역할 수행
- 싱크커넥터
- 커넥트 (Connect)
- 단일 실행모드 커넥트
- 간단한 데이터 파이프라인을 구성하거나 개발용으로 사용
- 분산 모드 커넥트
- 상용에 활용됨
- 여러개의 프로세스를 한개의 클러스터로 묶어서 운영하는 방식
- 일부 커넥트에 장애가 발생하더라도 파이프라인을 자연스럽게 failover하여 나머지 실행중인 커넥트에서 데이터를 지속적으로 처리하도록 도와줌
- 단일 실행모드 커넥트
- 커넥터와 커넥트의 관계
- 커넥트가 실행할때 커넥터가 어디에있는지 config파일에 위치를 지정해야함
- 커넥터 jar 패키지가 있는 디렉토리를 config 파일에 지정
- 실행중인 커넥트에서 커넥터를 실행하려면 REST API를 통함
- REST API를 통한 분산 모드 커넥트가 실행되게 됨
Kafka Mirror maker

- 특정 카프카 클러스터에서 다른 카프카 클러스터로 Topic 및 Record를 복제하는 Standalone tool
- 2019년 11월 기존 MirrorMaker를 개선한 MirrorMaker2.0 Release
- 클러스터간 토픽에 대한 모든 것을 복제하는 것이 목적
- 신규 토픽, 파티션 감지기능 및 토픽 설정 자동 Sync 기능
- 양방향 클러스터 토픽 복제
- 미러링 모니터링을 위한 다양한 metric(latency, count 등) 제공

+ Confluent의 Kafka cloud 서비스
- 카프카를 SaaS 형태로 사용하는 두가지 방법
- 1) AWS의 MSK(Managed Streaming for Kafka)
- 2) Confluent의 Cloud Kafka
'네트워크 & 인프라' 카테고리의 다른 글
AWS 컨테이너 ( ECS, EKS, 파게이트, ECR ) (0) 2022.11.04 ArgoCD (0) 2022.11.02 쿠버네티스 ⑤ Namespace 와 Helm (0) 2022.10.12 쿠버네티스 ④ Minikube 와 Kubectl, K8s YAML configuration File (0) 2022.10.12 쿠버네티스 ③ 기본 Architecture (1) 2022.10.12 - high throughput message capacity